1/ Giới thiệu
Trong thế giới Java, hiểu được JVM và Java Memory Model (JMM) không chỉ giúp bạn viết code đúng — mà còn mở khóa khả năng nắm vững cách Java vận hành từ lõi. JVM không phải là một “hộp đen”: nó quản lý bộ nhớ, nạp class, thực thi bytecode và tối ưu hiệu năng qua Interpreter, JIT Compiler và Garbage Collector.
JMM đảm bảo tính nhất quán bộ nhớ và visibility giữa các thread, giúp Java tránh race-condition và các lỗi đa luồng khó nắm bắt.
Trong bài viết này, bạn sẽ được khám phá kiến trúc JVM chi tiết, từ class loader, các vùng bộ nhớ Heap, Stack, Metaspace, đến cách Execution Engine vận hành, cùng sơ đồ trực quan minh họa luồng dữ liệu và vòng đời object. Đây là nền tảng để bạn làm chủ hiệu năng ứng dụng, tối ưu hệ thống và gỡ lỗi đa luồng một cách dễ

dàng.
2/ JVM được xây dựng thế nào? - Kiến trúc nền tảng
Để hiểu JVM thực sự làm gì, bạn cần nhìn JVM không phải như một “hộp đen chạy Java”, mà là một hệ thống runtime component-based gồm 3 thành phần chính:
- Class Loader System
- Runtime Data Areas (Heap, Stack, Meta/Perm)
- Execution Engine (Interpreter + JIT Compiler)
2.1/ Class Loader Subsystem
2.1.1 ClassLoader Subsystem là gì?
Class Loader Subsystem là cơ chế giúp JVM tải class vào memory theo từng nhu cầu. Đây là trái tim của tính linh hoạt, dynamic loading, hot deployment của Java.
Khi một class được JVM sử dụng, JVM không thể chạy trực tiếp file .class trên disk và phải load vào memory vì:
- VM cần cấu trúc hóa class để thực thi: File .class là dạng binary theo định dạng ClassFile, JVM cần chuyển nó thành các cấu trúc nội bộ:
- metadata về class (tên class, cha, interface…)
- constant pool đã được parse
- danh sách field, method
- bytecode của từng method
- thông tin access flags
- thông tin runtime cần cho reflection
- layouts để cấp phát object trên heap
- Tăng tốc thực thi: Nếu JVM phải đọc lại file từ disk mỗi lần gọi method → performance sẽ sụp đổ. Khi được load vào JVM, các class sẽ được:
- cache trong Method Area / Metaspace
- JIT có thể tối ưu
- Reflection có thể truy xuất metadata ngay lập tức
- GC có thể quản lý object thuộc class đó
- Các method có thể gọi lẫn nhau mà không phải đọc file lại
- Hỗ trợ runtime features với các tính năng như:
- Reflection
- Dynamic proxy
- JIT compilation
- Annotations
- Class redefinition (hot swap trong debug)
- CDI / Spring DI (scan class, load metadata)
Với những lí do và các tính năng ở trên, các class đều bắt buộcphải nằm trong memory để JVM và frameworks có thể đọc metadata của nó.
Vậy, tại sao JVM lại load các class on-demand mà không load hết một lượt rồi chỉ việc sử dụng?
JVM dùng mô hình Lazy Loading (Load-on-demand) để tối ưu resource và startup time. Điều này được thiết kế vì 3 lý do lớn:
- Tối ưu memory – tránh “ngốn RAM” không cần thiết
Các ứng dụng Java có thể có:
- hàng ngàn class
- hàng trăm JAR
- framework khổng lồ như Spring Boot, Hibernate
Trên thực tế, không phải tất cả các class trong Java đều được dùng ở runtime. Nó chỉ load class khi cần:
- Khi tạo mới 1 đối tượng object
- khi gọi method static
- khi access field
- khi reflective lookup
- khi JIT tối ưu luồng thực thi
Nếu những class, jar của framwork được load hết tất cả vào JVM trong lúc start-up, thì RAM của bạn sẽ như 1 nhà kho tổng hợp, phình to và chứa tất cả mọi thứ. Khi này, điều gì sẽ xảy ra:
- Metaspace sẽ phình to vô nghĩa
- Startup time tăng
- Gây tốn cả memory lẫn CPU
- Tối ưu thời gian khởi động (Startup Time)
Hãy tưởng tượng, nếu JVM phải load 30k class khi start một Spring Boot app → thời gian startup sẽ tăng gấp nhiều lần.
Lazy loading giúp:
- bật JVM cực nhanh
- load class nào cần chạy trước
- các class ít dùng thì không bị load vô ích
Ví dụ:Bạn có 100 REST endpoints nhưng hôm nay user chỉ gọi 10 cái → JVM chỉ cần load các class liên quan 10 endpoint này.
- Dynamic Loading
Java được sinh ra để chạy ứng dụng phân tán, lớn, nhiều module, nơi mà hệ thống phải mở rộng và thay đổi mà không cần dừng ứng dụng:
- Load plugin tại runtime (Runtime Extensibility)
- Bạn có thể thêm tính năng mới chỉ bằng cách đưa một file JAR vào thư mục plugin. Không cần rebuild, không cần restart app.
- Ví dụ: IntelliJ, Jenkins… đều load plugin nhờ dynamic class loading.
- Thay đổi implementation qua interface mà không restart
Bạn có thể:
- thay đổi driver database
- đổi provider gửi email
- đổi engine template…
…và ứng dụng vẫn chạy bình thường, vì JVM chỉ nạp implementation đúng khi class đó được sử dụng.
Đến đây, sẽ có 1 câu hỏi là: Vậy tại sao spring boot khi thay đổi configuration database, email provider hay bean thì cần phải restart?
Điều này phụ thuộc vào cách spring framework hoạt động, không phải của JVM:
``` App → ClassLoader → Load classpath → Run
```
- Khi bạn đổi driver hoặc đổi implementation, class mới không tồn tại trên classpath cũ.
- Không có cách unload class cũ (JVM cố tình cấm).
- Spring không tạo classloader mới cho toàn bộ app (chỉ tạo cho devtools).
→ Restart là cách đơn giản và an toàn nhất
- Hot deploy / Hot swap
Nhiều nền tảng hỗ trợ hot deploy/ hot swap:
- Spring DevTools
- JRebel
- Java Instrumentation API
Các nền tảng này dựa hoàn toàn vào khả năng JVM nạp lại class mới thay cho class cũ khi ứng dụng đang chạy.
- Hệ thống module: OSGi, Java Module System (JPMS)
OSGi tạo ra nhiều ClassLoader tầng lớp, mỗi bundle có class loader riêng → module có thể:
- được load/unload độc lập,
- nâng cấp nóng (hot upgrade),
- tránh xung đột dependency (class shadowing / class hiding).
- Tải class từ network – triết lý nguyên thủy của Java (Applets)
Ngày xưa Java Applet cho phép JVM download class từ internet và chạy ngay lập tức trong browser, dynamic loading vẫn là nền tảng của cơ chế này.
Ví dụ thực tế nhất: Spring Boot
Spring Boot dựa gần như 100% vào dynamic class loading:
- Nạp bean khi được reference hoặc khi container khởi tạo context
- Nạp configuration theo profile hoặc điều kiện (@Conditional)
- Load dependency module theo runtime environment
- Load class từ thư viện ngoài (external JARs) qua nhiều class loader khác nhau
Nếu Spring Boot bị ép phải load toàn bộ class ngay từ đầu:
- startup time = thảm họa
- RAM tăng vọt
- không còn hot reload / không còn conditional loading
Mục tiêu của Class Loader:
- Tải .class chứa bytecode vào JVM và chuyển chúng thành các đối tượng class trong bộ nhớ heap
- Class Loader đọc các file .class (hoặc byte stream từ JAR, mạng, custom source…) và chuyển chúng thành Class object trong bộ nhớ, phục vụ cho việc thực thi.
- Xây dựng dependency graph
- Khi một class được load, JVM sẽ tự động load:
- superclass, class
- interface
- type của fields
- type của methods → từ đó hình thành một đồ thị phụ thuộc giữa các class.
- Khi một class được load, JVM sẽ tự động load:
- Tách biệt namespace giữa các module
- Mỗi class loader có namespace riêng → hai class cùng tên nhưng được load bởi hai loader khác nhau sẽ được coi là hai class độc lập.Điều này giúp:
- cô lập ứng dụng (Tomcat webapps riêng biệt)
- hỗ trợ plugin (OSGi)
- tải lại class mà không ảnh hưởng ứng dụng khác
- Mỗi class loader có namespace riêng → hai class cùng tên nhưng được load bởi hai loader khác nhau sẽ được coi là hai class độc lập.Điều này giúp:
- Hỗ trợ sandboxing + security kiểm soát class đến từ đâu
- Class Loader kiểm soát:
- class load từ đâu (file, network, custom)
- có được phép load hay không → đảm bảo môi trường bảo mật của JVM.
- Class Loader kiểm soát:
- Cho phép custom class loader (OSGi, Spring Boot, app server như Tomcat/JBoss)
- Lập trình viên có thể tự viết Class Loader để:
- load class từ DB
- generate class động (ByteBuddy, ASM)
- hot reload (Spring Boot DevTools, Tomcat)
- quản lý module (OSGi)
- Lập trình viên có thể tự viết Class Loader để:
Class Loader được chia thành 3 loại:
- Bootstrap ClassLoader
- Extension/Platform ClassLoader
- Application ClassLoader
Nguyên tắt hoạt động:
- JVM khởi động → bootstrap class loader được khởi tạo ngầm định trong native code.
- Nó tìm và load các class lõi của JRE từ rt.jar hoặc Java Runtime Image.
- Khi một class khác cần load (ví dụ: java.sql.Connection), JVM sẽ delegation lên bootstrap loader trước, nếu không tìm thấy thì mới gọi class loader con (extension, application, custom). Điều này tuân thủ theo nguyên tắt Parent First, đảm bảo rằng lớp lõi của JVM không bị ghi đè hoặc thay đổi bởi các class loader khác
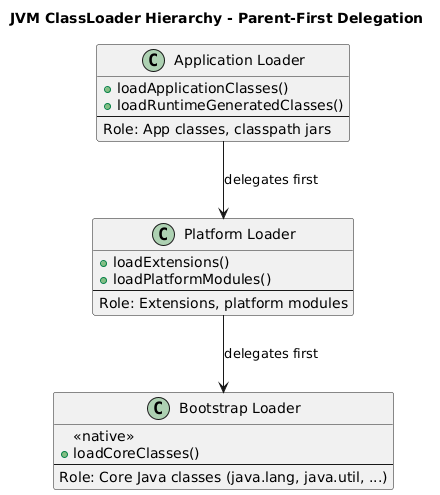
2.1.2/ Bootstrap Class Loader
Trong kiến trúc JVM, Bootstrap Class Loader (hay Primordial Class Loader) là class loader cơ bản và cao nhất, đóng vai trò nền tảng để JVM khởi chạy. Nó là “mảnh ghép” đầu tiên tạo ra môi trường chạy Java, bởi vì không gì trong JVM có thể hoạt động nếu các lớp cơ bản chưa được load.
Bootstrap Class Loader chịu trách nhiệm load các lớp lõi của Java, cụ thể là những lớp thiết yếu để JVM hoạt động:
- java.lang.Object – lớp gốc của mọi object trong Javajava.lang.String – lớp xử lý chuỗi cơ bản
- Các lớp thuộc java.lang, java.util, java.io, … nằm trong Java Runtime Environment (JRE)
Nói cách khác: mọi class loader khác, mọi class khác, đều dựa vào các lớp do bootstrap class loader nạp trước.
Một số đặc điểm nổi bật:

Vậy tại sao Bootstrap Class Loader lại quan trọng?
- Tạo nền tảng cho JVM chạy: Mọi class loader khác phụ thuộc vào nó.
- Đảm bảo an toàn: Không ai có thể override các lớp lõi (java.lang.*) vì bootstrap loader đứng trên cùng.
- Khởi tạo environment cho runtime: Heap, stack, code cache, GC, JIT… đều cần các lớp cơ bản do bootstrap loader load trước.
- Hỗ trợ module system (Java 9+): Quản lý lớp lõi theo module, giúp JVM nhỏ gọn hơn, dễ phân tách và bảo mật.
2.1.3/ Extension/Platform ClassLoader
Trong Java ClassLoader Hierarchy, sau Bootstrap ClassLoader, lớp tiếp theo là Extension ClassLoader (trong Java 9+ được gọi là Platform ClassLoader). Đây là một thành phần quan trọng, chịu trách nhiệm load các thư viện mở rộng và các module nền tảng, bổ sung tính năng cho core Java.
Trước Java 9, các extension được load từ Java extension directories ($JAVA_HOME/jre/lib/ext). Các class này bao gồm:
- JDBC drivers
- Security providers
- Các thư viện mở rộng chuẩn khác
Từ Java 9+, Class Loader này được đổi thành Platform ClassLoader, chịu trách nhiệm load platform modules, là thành phần chính trong Java Platform Module System (JPMS)
Một số điểm cần chú ý khi làm việc với Extension/Platform ClassLoader
- Precendence & versioning: Những classes được load bới Extension/Platform ClassLoader được ưu tiên hơn so với Application ClassLoader. Do đó, những classes tồn tại ở extension directory và application classpath, nếu không được quản lí cẩn thận thì có thể dẫn tới conflicts vì JVM sẽ dùng version ở Extension/Platform ClassLoader
- Security Implications: Vì Platform Loader nằm trên Application Loader trong loader hierarchy, nên JVM sẽ xem chúng là “trusted libraries”. Ngoài ra những classes này có có quyền cao hơn ở Application Loader, nên khi deploy cần chú ý khong để các “Non Trusted” class được lọt vào extension directories, và cần kiểm soát access permission của các class trong Platform
2.1.4/ Application Class Loader
Trong Java ClassLoader Hierarchy, Application ClassLoader (hay còn gọi là System ClassLoader) là lớp loader cuối cùng trong mô hình parent delegation, chịu trách nhiệm load các lớp của ứng dụng và các thư viện bên ngoài. Đây là loader mà các developer thường trực tiếp tương tác khi chạy project hoặc sử dụng classpath.
Loader này sẽ load application code, bao gồm:
- Load từ classpath:
- Code do bạn viết
- Từ các thư viện bên ngoài (JARs, directories)
- Các thư mục hoặc các vùng được định nghĩa thông qua:
- Environment CLASSPATH
- Command-line option: -cp hoặc -classpath
Application Loader cũng có hỗ trợ dynamic class loading thông qua những kỹ thuật:
- Reflection: Class.forName("com.example.MyClass")
- Proxy classes hoặc bytecode generation: Spring AOP, Hibernate, ByteBuddy
Các lớp này được nạp vào JVM Method Area / MetaSpace, instances được tạo trên Heap, stack frames được tạo trên thread stack khi method gọi.
Vì là lớp loader cuối cùng trong mô hình parent delegation, nên loader này có thể thấy được những class do parent load, nhưng các class của nó không được parent nhìn thấy. Điều này đảm bảo rằng, Core classes và Platform Modules không bị ghi đè và ứng dụng có thể load các class cần thiết mà không ảnh hưởng đến JVM.
Ví dụ:
```java
java -cp myapp.jar com.example.Main
```
- JVM sử dụng Application ClassLoader để tìm `myapp.jar` trên classpath
- Load `com.example.Main` và các class dependencies từ JAR
- Nếu class không có trong parent loader hoặc classpath -> throw ClassNotFoundException
2.2/ Runtime Data Area
2.2.1/ Runtime Data Areas là gì?
Runtime Data Areas là tập hợp các vùng bộ nhớ được JVM tạo ra và quản lý trong suốt vòng đời của ứng dụng.
Java Virtual Machine (JVM) chia bộ nhớ thành nhiều phần riêng biệt để phân loại không gian bộ nhớ dựa trên mục đích sử dụng. Ý tưởng chính là giúp nhanh chóng xác định mức độ sử dụng xấp xỉ của một đối tượng cụ thể và chỉ tập trung vào những đối tượng thực sự quan tâm.
Các vùng dữ liệu này được thiết kế rất cẩn thận để đảm bảo:
- Isolation giữa các Thread
- Hiệu năng khi thực thi bytecode
- An toàn bộ nhớ (Memory safety)
- Khả năng gom rác (GC) tối ưu
- Hỗ trợ đa nền tảng (nhờ một mô hình trừu tượng hóa phía dưới)
Mỗi phân vùng có vai trò khác nhau trong quá trình:
- tải lớp (class loading),
- thực thi bytecode,
- lưu trữ đối tượng,
- lưu biến cục bộ,
- quản lý lời gọi hàm,
- hỗ trợ cho native code.
Một số vùng sẽ dùng chung cho tất cả các Thread, một số vùng được tạo riêng cho từng Thread để đảm bảo an toàn dữ liệu.
Kiến trúc tổng quan của Runtime Data Areas - Java Memory Model:
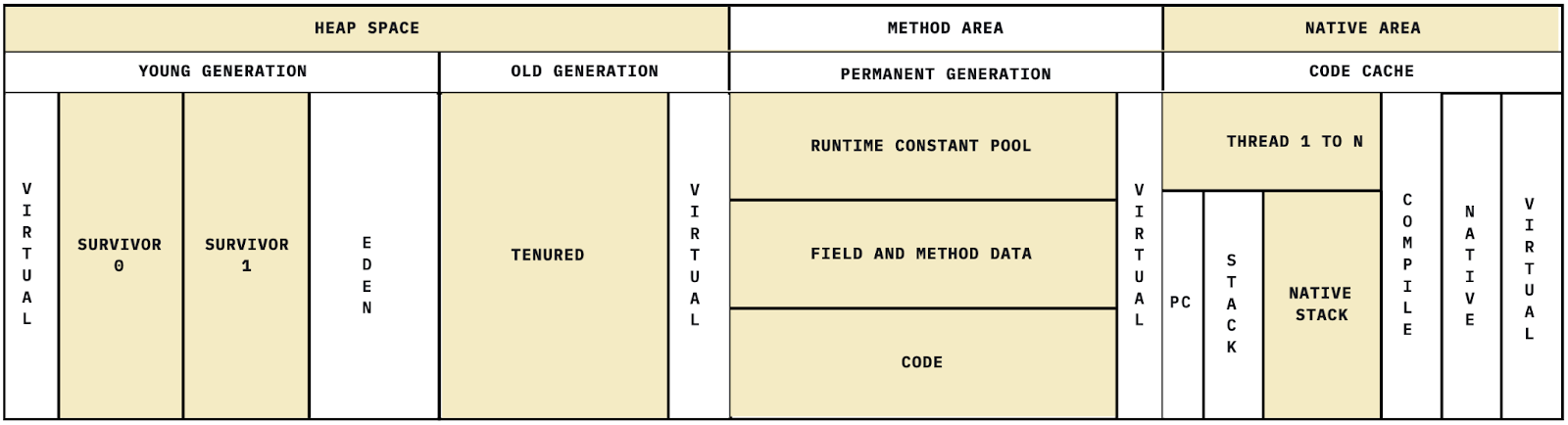
2.2.2/ Shared Areas (Vùng nhớ dùng chung cho tất cả các Thread)
JVM có một số vùng dữ liệu dùng chung được chia sẽ giữa tất cả các thread dang chạy trong JVM. Do đó, các Thread có thể đồng thời truy cập vào bất kì vùng trong trong các vùng này
2.2.2.1 HEAP
2.2.2.1.1 Heap là gì?
Heap là “ngôi nhà chung” - dùng để lưu tất cả các object trong JVM. Mỗi JVM chỉ có 1 heap, vì vậy heap được chia sẽ giữa tất cả các threads. Điều này giúp tiết kiệm bộ nhớ và cho phép đa luồng thao tác trên cùng object (cần synchronization nếu có).
Khi 1 object được khởi tạo thông qua từ khóa “new”, một vùng nhớ trong heap sẽ được cấp phát để lưu trữ object đó. Heap lưu trữ instance data và reference fields, nhưng không chứa method code - code của method được lưu trong Method Area.
Heap được khởi tạo khi JVM khởi động.
Heap memory được quản lý bởi Garbage Collector (GC) - một hệ thống tự động gom rác sẽ tự động thu hồi các object không còn được sử dụng trong java trong JVM đảm nhiệm.
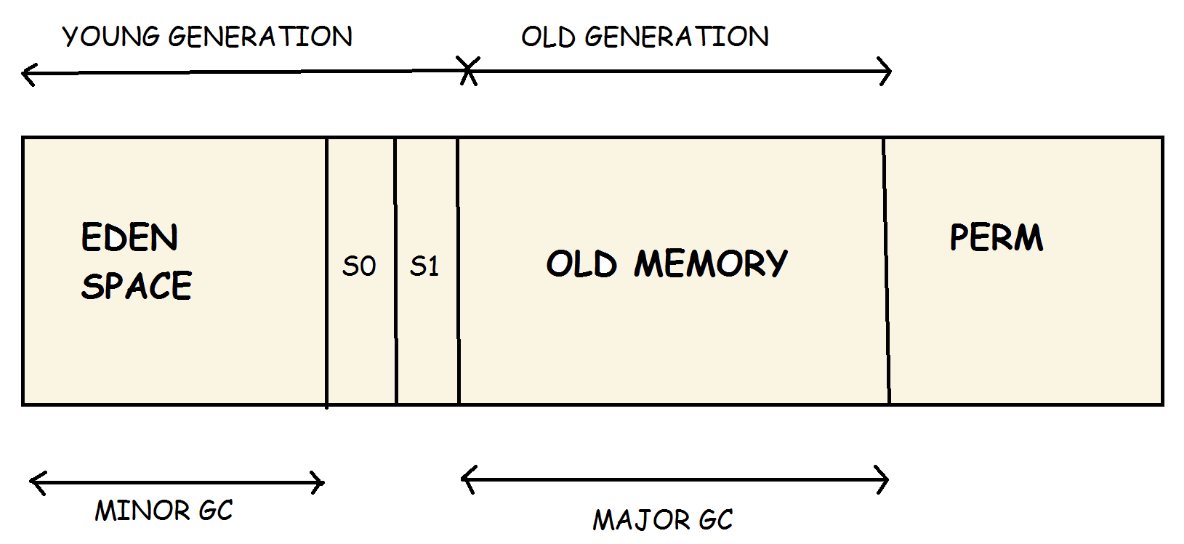
Heap được chia như thế nào?
Máy ảo cổ điển (HotSpot trước Java 8)
- Young Generation
- Old Generation
- Permanent Generation (PermGen) → chứa metadata lớp
JVM hiện đại (Java 8+)
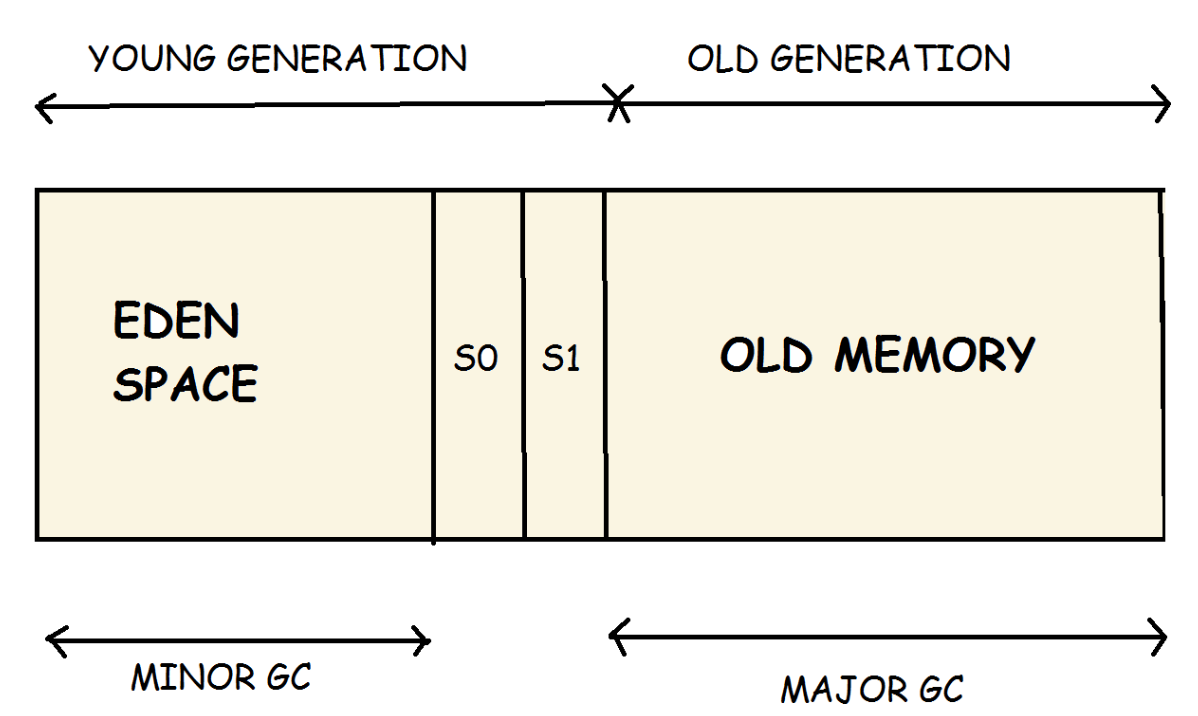
- Young Generation
- Old Generation
- Metaspace (thay cho PermGen, nằm trong native memory)
Ở phần này, chúng ta sẽ tập trung vào 2 phần Young Generation và Old Generation - phần quan trọng nhất để quyết định performance:
2.2.2.1.2 Young Generation
Young Generation là vùng bộ nhớ nơi tất cả các đối tượng mới được tạo ra. Khi vùng nhớ Young Generation đầy, JVM sẽ thực hiện garbage collection. Việc thu gom rác trong vùng Young Generation được gọi là Minor Garbage Collection.
Young Generation được chia thành ba phần: Eden và hai vùng Survivor (S0 và S1).
Eden (nơi object sinh ra)
- 90% object mới tạo ra tại đây
- Khi đầy → Minor GC được kích hoạt
Survivor 0 & Survivor 1
- Sau mỗi lần GC, object còn sống được copy từ Eden → S0 → S1 → Old Gen
- JVM dùng copying algorithm, luôn có một vùng Survivor trống
Những đặc điểm chính về Young Generation:
- Hầu hết các đối tượng mới tạo đều nằm trong vùng nhớ Eden.
- Khi vùng Eden đầy đối tượng, Minor GC được kích hoạt và các đối tượng còn sống (survivor objects) được chuyển sang một trong hai vùng Survivor.
- Minor GC tiếp tục kiểm tra các đối tượng sống và chuyển chúng sang vùng Survivor còn lại. Vì vậy, luôn có một vùng Survivor trống.
- Các đối tượng sống sót qua nhiều vòng GC sẽ được chuyển sang vùng nhớ Old Generation.
2.2.2.1.3 Old Generation (Tenured Space)
Đây là nơi object sống lâu, đã “tốt nghiệp” từ Young Gen chuyển sang.
Đặc điểm:
- Chứa object lâu dài: session, cache, singletons
- GC chậm hơn (Major GC / Full GC)
- Sử dụng thuật toán Mark-Sweep-Compact
Khi nào object “lên lão”?
- Sống qua nhiều vòng GC trong Young Gen
- Hoặc Eden quá đầy → promotion sớm
- Hoặc object quá lớn → bypass Eden → đặt thẳng vào Old Gen
Vấn đề nguy hiểm:
- Full GC có thể dừng ứng dụng trong nhiều ms → vài giây
- Nếu Old Gen đầy → java.lang.OutOfMemoryError: Java heap space
2.2.2.1.4 Vòng đời của 1 object trong HEAP
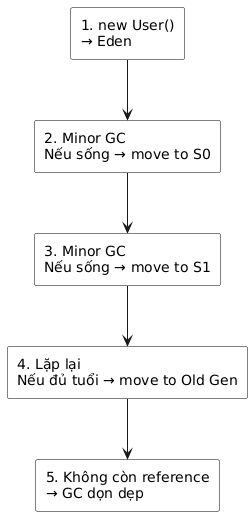
Lifecycle này giúp GC tối ưu việc xoá object chết và giữ object sống lâu hơn ở Old Gen để tăng hiệu suất và hạn chế vấn đề về memory leak.
2.2.2.1.5. Permanent Generation (PERM)
Trước Java 8, JVM có một vùng bộ nhớ đặc biệt gọi là Permanent Generation. Đây là nơi lưu trữ metadata của các lớp (classes).
Việc dự đoán lượng bộ nhớ cần dùng cho vùng này khá khó khăn. Khi dự đoán sai, JVM thường ném ra lỗi java.lang.OutOfMemoryError: PermGen space
Nếu nguyên nhân không phải do rò rỉ bộ nhớ (memory leak), cách phổ biến để khắc phục là tăng dung lượng PermGen, ví dụ như đặt giới hạn tối đa là 256 MB:
java -XX:MaxPermSize=256m
Các điểm chính về Permanent Generation:
- Chỉ tồn tại trong Java phiên bản dưới 8.
- Lưu trữ metadata của các class.
- Khó dự đoán mức sử dụng bộ nhớ.
2.2.2.1.6. Metaspace
Vì việc dự đoán nhu cầu bộ nhớ cho metadata là phức tạp và bất tiện, Permanent Generation đã bị loại bỏ từ Java 8, và thay thế bằng Metaspace. Từ phiên bản này trở đi, hầu hết các thành phần linh tinh được chuyển vào vùng heap thông thường của Java.
Các định nghĩa lớp (class definitions) được nạp vào Metaspace. Metaspace nằm trong native memory (bộ nhớ ngoài heap) nên không ảnh hưởng trực tiếp đến các đối tượng trong Java heap. Mặc định, kích thước Metaspace chỉ bị giới hạn bởi lượng bộ nhớ native còn lại của hệ thống dành cho tiến trình Java. Điều này giúp tránh tình trạng chỉ cần thêm một class nhỏ cũng khiến chương trình gặp lỗi:
java.lang.OutOfMemoryError: PermGen space
Các điểm chính về Metaspace:
- Để Metaspace phát triển không kiểm soát có thể dẫn đến swapping nặng và lỗi cấp phát bộ nhớ native.
- Nếu bạn muốn tự bảo vệ trước trường hợp này, bạn có thể giới hạn kích thước Metaspace, ví dụ đặt tối đa 256 MB:
java -XX:MaxMetaspaceSize=256m
2.2.2.2 Method Area
Tương tự như Heap, mỗi JVM cũng chỉ có duy nhất 1 method area, nên nó được chia sẽ giữa tất cả các threads với nhau. Điều này giúp tiết kiệm bộ nhớ, tránh trùng lặp metadata của cùng một class.
Các dữ liệu được chứa trong Method Area:

Tóm lại, nó là nơi JVM lưu trữ "bản thiết kế" của các lớp để thực thi chương trình
2.2.2.3 Runtime Constant Pool (RCP)
Là một phần quan trọng của Method Area, chứa:
- Các hằng số được biên dịch (int, long, string,…),
- Các tham chiếu đến class, fields và methods
Khi một class được load, Runtime Constant Pool của class đó cũng được tạo ra và chứa tất cả các hằng số liên quan, giúp JVM và các method truy cập nhanh chóng các tài nguyên này mà không cần phải phân tích lại mã nguồn.
Lưu ý: mặc dù RCP lưu trữ các chuỗi String, nhưng bản thân pool này nằm ở Method Area - Được tạo riêng trên mỗi class, mỗi interface khi thực thi. Trong khi String Pool ở Heap như và là 1 global pool shared giữa các classes
2.2.3. Per-thread Data Areas - Vùng nhớ dành riêng cho từng thread
Bên cạnh các “ngôi nhà chung” mà các thread có thể truy cập bất cứ lúc nào, JVM cũng tạo những “vùng đất riêng” trên mỗi thread để lưu trữ những thông tin, dữ liệu riêng biệt của các thread để hỗ trợ việc thực thi nhiêu thread cùng lúc.
2.2.3.1. PC Register
PC (Program Counter) Register là một thanh ghi đặc biệt trong mỗi thread của JVM, có nhiệm vụ lưu trữ địa chỉ bộ nhớ của bytecodes tiếp theo cần được CPU (JVM) thực thi, đóng vai trò "kim chỉ nam" điều khiển luồng thực thi chương trình, đảm bảo các lệnh được chạy đúng thứ tự hoặc nhảy đến vị trí khác theo logic chương trình
Mỗi thread chạy trong JVM có một bộ nhớ riêng gọi là JVM Stack, và mỗi frame trong stack này sẽ có một PC Register riêng, giúp quản lý việc thực thi độc lập giữa các thread bằng cách:
- Theo dõi tiến độ thực thi của frame đó
- Ghi nhớ bytecode hiện tại/kế tiếp cần chạy
Vì vậy, PC Register là một phần của thread context, dùng để lưu vị trí bytecode trong context của từng thread và hoàn toàn không chia sẽ giữa các thread với nhau
Mối liên hệ giữa PC Register và Thread Scheduler của OS
Trên bất kể hệ điều hành nào (Linux, Windows, macOS):
- CPU không thể chạy nhiều thread thật sự cùng lúc trên cùng một core
- OS sẽ quyết định:
- thread nào được chạy
- chạy trên core nào
- chạy trong bao lâu
- khi nào chuyển sang thread khác (context switch)
→ JVM không điều khiển scheduling, mà phụ thuộc vào OS.
Việc của JVM là cần chuẩn bị 1 “bộ context riêng” (thread context) cho mỗi thread, gồm:
- Stack: Chứa các stack frame khi gọi hàm
- Local variable: Biến cục bộ của thừng method chỉ thuộc về thread đó
- PC Reigster: Lưu điểm bytecode kế tiếp mà thread này sẽ chạy
Điều này chứng tỏ PC Register là một phần của thread context mà OS sẽ lưu hoặc khôi phục khi chuyển thread (context switch).
Khi OS thực hiện context switch, điều gì sẽ xảy ra? Hãy làm rõ vấn đề thông qua ví dụ sau:
Hãy xem xét một tình huống thực tế khi Thread A đang chạy và hệ điều hành (OS) quyết định chuyển CPU sang Thread B. Lúc này, OS thực hiện quy trình gọi là context switch (chuyển ngữ cảnh). Đây là nơi vai trò của PC Register thể hiện rõ nhất.
Bước 1. OS tạm dừng Thread A – Lưu lại toàn bộ trạng thái CPU
Để có thể quay lại đúng chỗ sau này, OS phải lưu lại toàn bộ bối cảnh thực thi của Thread A, bao gồm:
- Các CPU registers (eax, ebx, r1, r2… tùy kiến trúc CPU)
- Stack pointer (SP) → trỏ vào frame hiện tại trong stack của thread
- CPU flags (trạng thái carry, zero, sign…)
- PC Register của Thread A → đây là thông tin quan trọng nhất
- PC của Thread A lưu lại địa chỉ bytecode hoặc instruction tiếp theo sẽ được chạy.
- PC của Thread A lưu lại địa chỉ bytecode hoặc instruction tiếp theo sẽ được chạy.
Bước 2: OS chuyển sang Thread B – Phục hồi trạng thái của Thread B
- Load lại PC Register của Thread B
- Cho CPU biết lần trước Thread B đang dừng ở instruction nào
- Load lại các CPU registers của Thread B
- Phục hồi stack pointer của Thread B
- CPU tiếp tục chạy từ vị trí mà PC của Thread B chỉ định
Khi này, PC Register chính là “tọa độ” để OS có thể quay lại và tiếp tục tại chính xác dòng lệnh mà thread đã dừng.
Vậy, vì sao PC Register quan trọng trong lập trình đa luồng?
- Khi nhiều thread chạy đồng thời, JVM cần biết thread nào đang ở instruction nào
- PC Register riêng cho mỗi thread đảm bảo không nhầm lẫn giữa các luồng, giúp chương trình chạy mượt mà, đúng thứ tự, tránh race condition trong logic bytecode (control flow).
Vì sao mỗi thread có 1 PC Register giúp tránh race condition trong logic bytecode?
Mỗi thread có một PC Register riêng, chứa địa chỉ bytecode kế tiếp sẽ được thực thi. Nhờ đó, khi nhiều thread chạy song song, thread A và thread B luôn biết chính xác mình đang ở đâu trong chuỗi bytecode của chính nó, mỗi thread phải tiếp tục tại điểm nó đang xử lí, không bị ảnh hưởng bởi thread khác.
Nếu không có PC Register riêng cho mỗi thread, chỉ cần thread thay đổi PC, tất cả các thread khác đều sẽ chạy sai vị trí. Hãy tưởng tượng rằng chương trình của bạn đang có 2 threads đang cùng chạy song song, và chỉ có 1 PC cho chúng:
- Thread A đang thực thi đến lệnh số 120
- Thread B nhảy vào làm thay đổi PC sang lệnh 45 → Khi Thread A quay lại, nó sẽ chạy từ lệnh 45 (trong khi lẽ ra phải chạy 121) → logic chương trình bị hỏng.
Nhờ mỗi thread có PC riêng:
- Thread A tự quản lý đường đi bytecode của nó
- Thread B cũng tự quản lý đường đi bytecode riêng → Không bao giờ có chuyện “tranh nhau chỉnh PC”, cũng không có chuyện thread này làm lệch luồng điều khiển của thread kia.
Nhìn chung, ta có thể hiểu rằng PC Register giúp tránh race condition trong “luồng điều khiển” (control flow). Nhưng chính xác hơn thì: PC Register là nơi JVM lưu vị trí bytecode hiện tại của từng thread, hay nói cách khác: nó là một phần quan trọng của thread context. Nhưng PC Register một mình chưa đủ để đảm bảo tính nhất quán - vì PC chỉ hoạt động khi thread đang chạy trên CPU, nếu thread dừng, PC sẽ dừng hoạt động và giá trị của nó sẽ được lưu lại. Tại đây OS Scheduler đóng vai trò then chốt khi đảm bảo rằng mỗi CPU core chỉ thực thi đúng 1 thread tại một thời điểm, không thể thực thi 2 context song song trên cùng 1 CPU. Điều này ngăn chặn xung đột control flow ngay từ cấp độ CPU.
Nói cách khác, OS Scheduler ngăn race condition ở cấp độ CPU, còn PC Register ngăn race condition ở cấp độ bytecode của từng thread.
2.2.3.2. Java stack
Java stack là nơi JVM quản lý các lời gọi phương thức và biến cục bộ (biến nguyên thủy, tham chiếu đối tượng) cho một thread.
Mỗi khi một phương thức được gọi, một frame mới được tạo ra trên Stack để lưu trữ các biến cục bộ của nó. Khi phương thức kết thúc, frame đó sẽ bị loại bỏ khỏi Stack, bộ nhớ được giải phóng.
LIFO (Last-In FIrst-Out) là nguyên tắt quản lí dữ liệu của stack.
Vai trò chính:
- Quản lý vòng đời phương thức Java
- Lưu trữ biến cục bộ và tham số
- Lưu trữ metadata liên quan đến thực thi
- Quản lý stack frames theo LIFO
Cấu trúc của Java Stack Memory
Java Stack được chia thành các Stack Frame, mỗi frame tương ứng với một lời gọi phương thức.
Một Stack Frame gồm:
- Local Variable Array
Lưu trữ:
- Các biến cục bộ (primitive: int, long, boolean,…)
- Tham số truyền vào method
- Object references trỏ vào vùng nhớ Heap
Lưu ý: Java lưu object trên Heap, reference trên Stack.
- Operand Stack:
Đây là nơi JVM thực hiện các phép tính.Bytecode không dùng thanh ghi như CPU, mà dùng operand stack để:
- push giá trị
- tính toán
- pop kết quả
- Frame Data (Additional Info)
Chứa metadata phục vụ quá trình thực thi:
- reference tới constant pool của class
- độ sâu tối đa của operand stack
- các exception handler
- return address
Các thông tin này giúp JVM:
- biết bytecode cần chạy
- định tuyến exception
- quay trở lại caller sau khi method kết thúc
Lưu ý: Đây là 1 vùng nhớ được quản lí bởi JVM, không phải kiểu dữ liệu Stack thuộc Java Collections Framework.
2.2.3.3. Native Method Stack
Native Method Stack là một phần ít được chú ý nhưng đóng vai trò cực kỳ quan trọng khi Java cần tương tác với mã lệnh hệ điều hành hoặc thư viện viết bằng C/C++. Đây là thành phần nằm trong Runtime Data Areas, hoạt động song song với Java Stack, Heap, Method Area, và PC Register.
Native Method Stack là nơi JVM “rẽ nhánh” sang đường đi native — nơi xử lý các tác vụ mà bytecode Java không thể hoặc không nên thực hiện, và được gọi thông qua JNI (Java Native Interface).
Nó hoàn toàn tách biệt với Java Stack (nơi chứa frame của các phương thức Java).
Nếu so sánh với Java Stack, ta có thể thấy được điểm khác biệt lớn nhất:

Vậy, Native Method Stack được sinh ra với mục đích gì?
Native Method Stack được thiết kế cho các tình huống mà Java không có khả năng thao tác trực tiếp, ví dụ:
- Tương tác với hệ điều hành: Truy cập tài nguyên OS-level, API hệ thống (mạng, thiết bị, driver…).
- Tối ưu hiệu năng: Một số tác vụ tính toán chuyên sâu hoặc xử lý low-level sẽ nhanh hơn khi viết bằng C.
- Gọi thư viện hệ thống hoặc bên thứ ba: Nhiều thư viện chỉ tồn tại dưới dạng C/C++ (OpenSSL, đồ họa, codec…).
- Native code bên trong JVM: Ngay cả JVM nội bộ cũng dùng native methods (ví dụ: Object.wait(), System.arraycopy()).
Cấu trúc và cách hoạt động
Native Method Stack hoạt động tương tự Java Stack:
- Mỗi thread có một Native Method Stack riêng (thread-local).
- Nguyên tắc hoạt động: LIFO – Last In, First Out.
- Mỗi lần gọi một phương thức native, JVM tạo một Native Frame để lưu:
- Các tham số truyền vào native method
- Con trỏ đến native function trong thư viện C/C++
- Các biến cục bộ native
- Trạng thái thực thi của JNI
- Thông tin để quay lại Java Stack sau khi method kết thúc
- Native Frame không giống Java Frame. Nó không lưu bytecode, mà lưu các cấu trúc phù hợp với ngôn ngữ C và hệ điều hành.
Khi nào Native Method Stack được sử dụng?
Trường hợp phổ biến:
- Một Java method được khai báo native:
``` java
public native int readFile(String path);
```
- Tại runtime, khi phương thức được gọi:
- JVM chuyển từ Java Stack sang Native Method Stack.
- Tạo Native Frame.
- Gọi hàm tương ứng trong thư viện *.so / *.dll / .dylib.
- Nhận kết quả và quay lại Java Stack.
Ví dụ quen thuộc trong JDK:
- System.nanoTime()
- System.loadLibrary()
- Thread.start()
- Class.forName0()
- Các hàm I/O (UNIX system calls)
2.3. Execution Engine
Đây là “bộ não” của JVM. Đây là thành phần trực tiếp đọc bytecode, chuyển đổi thành mã máy (machine code) và quản lý chu kỳ sống của object trong bộ nhớ.
Về căn bản, cấu trúc của “bộ não” này được cấu thành từ 3 phần chính:
- Interpreter – thông dịch và chạy bytecode theo từng lệnh
- JIT Compiler – biên dịch tối ưu các đoạn mã nóng (hot code path) thành mã máy
- Garbage Collector – tự động quản lý bộ nhớ và thu hồi object không còn được tham chiếu
2.3.1. Interpreter
Đây là bước khởi động đầu tiên trước khi Execution Engine thực thi bất kì 1 đoạn mã nào.
Mô hình hoạt động của Interpreter:
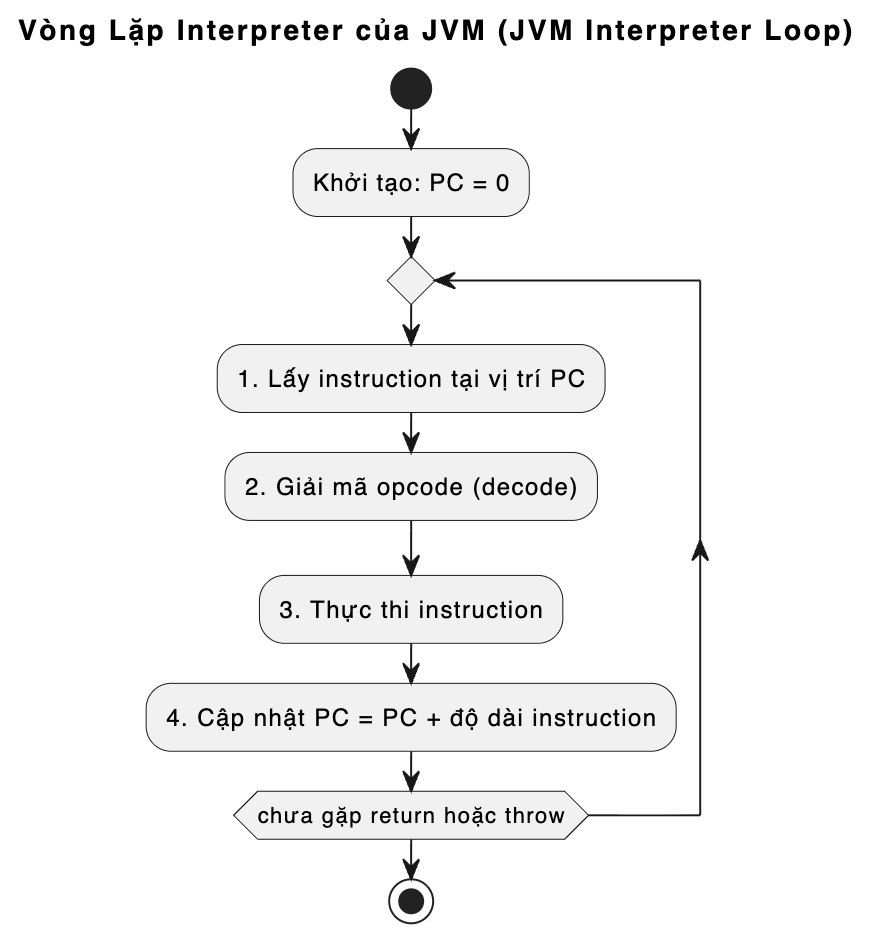
Đơn giản, có thể hiểu nguyên tắc hoạt động của JVM Interpreter như sau:
- Interpreter sẽ đọc các bytecode instruction trong PC register
- Giải mã các bytecode đã đọc
- Thực thi các đoạn mã đã được giải mã theo tuần tự
- Sau khi thực hiện xong đoạn mã, Interpreter sẽ tiếp tục vòng lặp để đọc bytecode instruction tiếp theo và tiếp tục lặp lại các bước
Ví dụ quá trình hoạt động:
Giả sử chúng ta có 1 method
```java
int sum(int a, int b) {
return a + b;
}
```
Bytecode được biên dịch:
```
0: iload_1 // load a
1: iload_2 // load b
2: iadd // add them
3: ireturn // return result
```
Interpreter sẽ thực thi các bước:

2.3.2. JIT Compiler - Just-In-Time compiler
JIT compiler là một trình biên dịch tối ưu của JVM, chịu trách nhiệm biên dịch mã bytecode thành mã máy gốc ngay trong lúc chương trình chạy ("just-in-time") để tối ưu hiệu suất, thay vì dịch toàn bộ trước khi chạy.
JIT xác định các đoạn mã thường xuyên được thực thi (hotspots) và biên dịch chúng thành mã máy hiệu suất cao, lưu vào bộ nhớ cache (Code Cache) để tái sử dụng, giúp ứng dụng Java chạy nhanh hơn đáng kể so với chỉ dùng trình thông dịch. Đây là cơ chế giúp Java đạt được hiệu năng cao, tương đương hoặc vượt qua nhiều ngôn ngữ biên dịch truyền thống như C++ trong các ứng dụng chạy lâu (long-running services).
Mô hình hoạt động của JIT compiler:
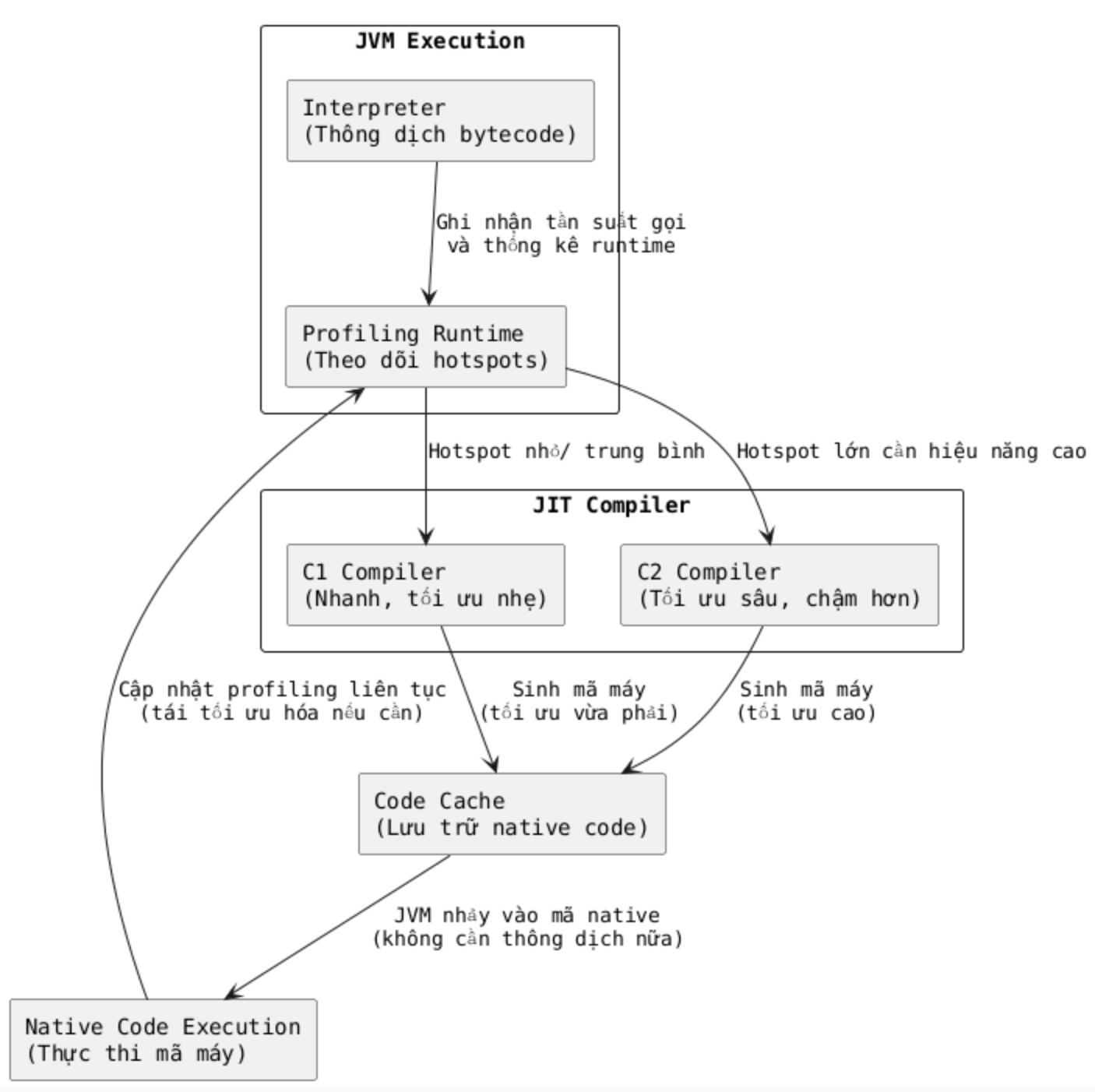
Vậy, vì sao JIT biết được 1 đoạn mã nào là hotspots?
JVM có một cơ chế gọi là HotSpot Profiling:
- Mỗi phương thức có một Invocation Counter
- Mỗi vòng lặp có một Back-edge Counter
Khi số lần gọi hoặc số lần lặp vượt qua “ngưỡng” (threshold), JVM đánh dấu đoạn code đó là hotspot.
➡ Nghĩa là JIT chỉ tối ưu đúng những gì thật sự quan trọng với hiệu năng.
JIT biên dịch bytecode sang native code như thế nào?
Khi một đoạn mã trở thành hotspot:
- JVM gửi bytecode sang JIT
- JIT thực hiện các tối ưu hóa nâng cao
- JIT biên dịch thành mã máy gốc của CPU (x86_64, ARM64, RISC-V, tùy nền tảng)
- Mã máy được lưu trong Code Cache
➡ Các lần thực thi sau chạy native code trực tiếp, không cần Interpreter nữa.
Vì sao JIT compiler lại tối ưu hơn Compiler thông thường của Java?
JIT có thể tối ưu tốt hơn compiler truyền thống vì:
JIT biết chính xác chương trình chạy như thế nào
Ví dụ: phương thức nào được gọi nhiều nhất, kiểu thực tế của đối tượng, branch nào luôn đúng,…
- Inlining: nhúng thân hàm vào nơi gọi → giảm overhead
- Dead Code Elimination: loại bỏ code không cần thiết
- Escape Analysis: xác định object có thể nằm trên stack thay vì heap
- Loop Unrolling: tối ưu vòng lặp
- Branch Prediction Optimization
Tối ưu hóa phổ biến:
➡ JIT tạo ra native code phù hợp nhất với runtime thực tế, giúp hiệu năng Java trong long-running background services cực kỳ cao.
Các loại JIT trong hotspots của JVM
HotSpot (JVM mặc định của Oracle/OpenJDK) dùng hai JIT Compiler chính:

Java 8+ dùng Tiered Compilation:
```
Interpreter ➡ C1 ➡ C2
```
2.3.3. Garbage Collector
Garbage Collector (GC) là một thành phần quan trọng trong Execution Engine của Java, chịu trách nhiệm quản lý bộ nhớ Heap tự động. GC giúp phát hiện và giải phóng các đối tượng không còn được tham chiếu (unreferenced objects), từ đó tránh rò rỉ bộ nhớ, giảm lỗi con trỏ, và tối ưu hiệu năng mà không yêu cầu lập trình viên quản lý thủ công như trong C/C++.
Nhờ GC, lập trình viên Java có thể tập trung vào logic nghiệp vụ thay vì phải quan tâm đến việc cấp phát và thu hồi bộ nhớ.
Cơ chế hoạt động:
- Xác định đối tượng gọi là “rác”:GC theo dõi toàn bộ các đối tượng trên Heap. Một đối tượng được coi là “rác” khi:
- Không còn bất kỳ biến hoặc tham chiếu nào trỏ đến nó.
- Không thể truy cập được từ GC Roots (Thread stacks, static fields, JNI references...).
Mô hình này gọi là reachability analysis — GC chỉ giữ lại các đối tượng có thể “với tới” từ GC Roots
- Thu hồi bộ nhớ (Memory Reclamation):
Khi đối tượng bị coi là rác, GC sẽ tự động xóa và thu hồi vùng nhớ của nó để phục vụ cho các yêu cầu cấp phát mới. Quá trình diễn ra hoàn toàn trong JVM, không yêu cầu lập trình viên can thiệp.
Lợi ích của GC:
- Giảm gánh nặng lập trình: Không cần `free()` hay `delete`. Điều này giảm rất nhiều chi phí tư duy.
- Ngăn chặn lỗi nguy hiểm: Giảm memory leak, dangling pointer
- Tối ưu hiệu suất
3. Lời tổng kết
JVM và JMM không chỉ là các chi tiết kỹ thuật — chúng là nền tảng tư duy để thiết kế ứng dụng Java hiệu năng cao, an toàn cạnh tranh, dễ mở rộng và concurrency.
Nắm vững chúng nghĩa là bạn hiểu những yếu tố quyết định việc sử dụng và xây dựng 1 ứng dụng concurrency trong java hiệu quả
- JVM và Java Memory Model (JMM)
- JMM xác định cách các thread nhìn thấy và cập nhật dữ liệu trong bộ nhớ.
- Quan trọng để tránh race condition và đảm bảo visibility khi nhiều thread truy cập cùng một object.
- Kiến thức về JMM là nền tảng để sử dụng volatile, synchronized, Atomic classes, hay concurrent collections đúng cách.
- Runtime Data Areas (Heap & Stack)
- Heap là vùng bộ nhớ chung cho tất cả các thread, nơi lưu object. Việc thao tác trên các object này cần đồng bộ nếu nhiều thread truy cập.
- Stack và PC Register là thread-local, đảm bảo rằng luồng điều khiển (control flow) của mỗi thread độc lập, tránh xung đột về logic bytecode.
- Metaspace / Method Area chứa class metadata, shared giữa thread, ảnh hưởng đến cách JVM quản lý class loading nhưng ít tác động trực tiếp đến data race.
- Class Loader Subsystem
- Cơ chế dynamic class loading và lazy loading giúp JVM quản lý memory và startup hiệu quả.
- Hiểu về ClassLoader hierarchy (Bootstrap → Platform → Application) giúp biết class nào có thể được chia sẻ giữa thread và class nào bị cô lập, điều này quan trọng khi thiết kế các module concurrency-safe.
- Execution Engine
- Interpreter & JIT Compiler: cung cấp kiến thức về cách bytecode được thực thi và tối ưu runtime.
- Hiểu cơ chế này giúp reasoning về happens-before relationship giữa các thread, đặc biệt khi JIT có thể reorder code hoặc tối ưu hóa memory access.
- Hiểu cơ chế này giúp reasoning về happens-before relationship giữa các thread, đặc biệt khi JIT có thể reorder code hoặc tối ưu hóa memory access.
- Garbage Collector:
- GC xử lý bộ nhớ heap chung, nên việc tạo và hủy object ảnh hưởng đến performance trong môi trường đa luồng.
- Hiểu lifecycle object (Young → Old Gen) giúp lập trình viên tối ưu object reuse và tránh tình trạng stop-the-world GC ảnh hưởng tới thread responsiveness.
- Interpreter & JIT Compiler: cung cấp kiến thức về cách bytecode được thực thi và tối ưu runtime.
- Per-thread Data Areas
- PC Register, Java Stack, Native Method Stack là các vùng thread-local, giúp mỗi thread thực thi độc lập mà không cần lock.
- Hiểu sự phân chia thread-local và shared memory là cốt lõi để quyết định khi nào cần synchronization, khi nào không.
Tóm lại:
- Shared memory (Heap, Method Area, Metaspace) → cần synchronization và visibility control.
- Thread-local memory (Stack, PC, Native Stack) → không cần lock, thread-safe tự nhiên.
- Class loading & execution → ảnh hưởng gián tiếp tới concurrency khi nhiều thread khởi tạo hoặc truy cập object, nhất là trong framework như Spring.
- Garbage Collection → cần hiểu để tránh stop-the-world pause ảnh hưởng tới multithreaded app performance.
- JMM fundamentals → nền tảng để reasoning về concurrency correctness.