By @wuan580
Trong thế giới khắc nghiệt của các hệ thống dữ liệu, mọi thứ đều có thể xảy ra:
- Phần mềm hoặc phần cứng cơ sở dữ liệu có thể bị lỗi bất cứ lúc nào (kể cả giữa thao tác ghi)
- Ứng dụng có thể sập giữa chừng, khi một loạt thao tác vẫn chưa hoàn tất.
- Sự cố mạng có thể bất ngờ cắt đứt ứng dụng khỏi cơ sở dữ liệu hoặc một nút cơ sở dữ liệu này khỏi nút khác.
- Nhiều client có thể ghi đồng thời, vô tình ghi đè lên thay đổi của nhau.
- Client có thể đọc dữ liệu vô nghĩa vì nó chỉ được cập nhật một phần.
- Race condition có thể âm thầm len lỏi, gây ra những lỗi không lường trước được
Để một hệ thống đáng tin cậy, nó phải có khả năng đối mặt và phục hồi trước những sự cố như vậy. Nhưng thiết kế một hệ thống chịu lỗi không hề đơn giản, nó đòi hỏi tư duy cẩn trọng, dự đoán những điều tệ nhất có thể xảy ra, và kiểm thử khắt khe để đảm bảo mọi thứ vẫn vững vàng khi có sự cố.
Và như một điều tất yếu, khái niệm Transaction ra đời như một lời đảm bảo rằng dù có chuyện gì xảy ra, dữ liệu vẫn đúng, hoặc là mọi thay đổi được thực hiện trọn vẹn, hoặc là không có gì được thực hiện cả.
Trong bài viết này, chúng ta sẽ khám phá chi tiết hơn về transactions, cách nó vận hành, những tính chất nổi bật, và vai trò quan trọng của chúng trong việc xây dựng các hệ thống đáng tin cậy.
1. Transaction là gì?
A transaction is a way for an application to group several reads and writes together into a logical unit. Conceptually, all the reads and writes in a transaction are executed as one operation: either the entire transaction succeeds (commit) or it fails (abort, rollback).
Transaction là một chuỗi các thao tác trên cơ sở dữ liệu (như đọc, ghi, cập nhật) được thực hiện như một đơn vị công việc thống nhất, đảm bảo tính toàn vẹn dữ liệu. Nó tuân theo nguyên tắc "all or nothing", nghĩa là hoặc tất cả các thao tác trong transaction đều thành công, hoặc không thao tác nào được áp dụng nếu có lỗi xảy ra.
2. The Meaning of ACID
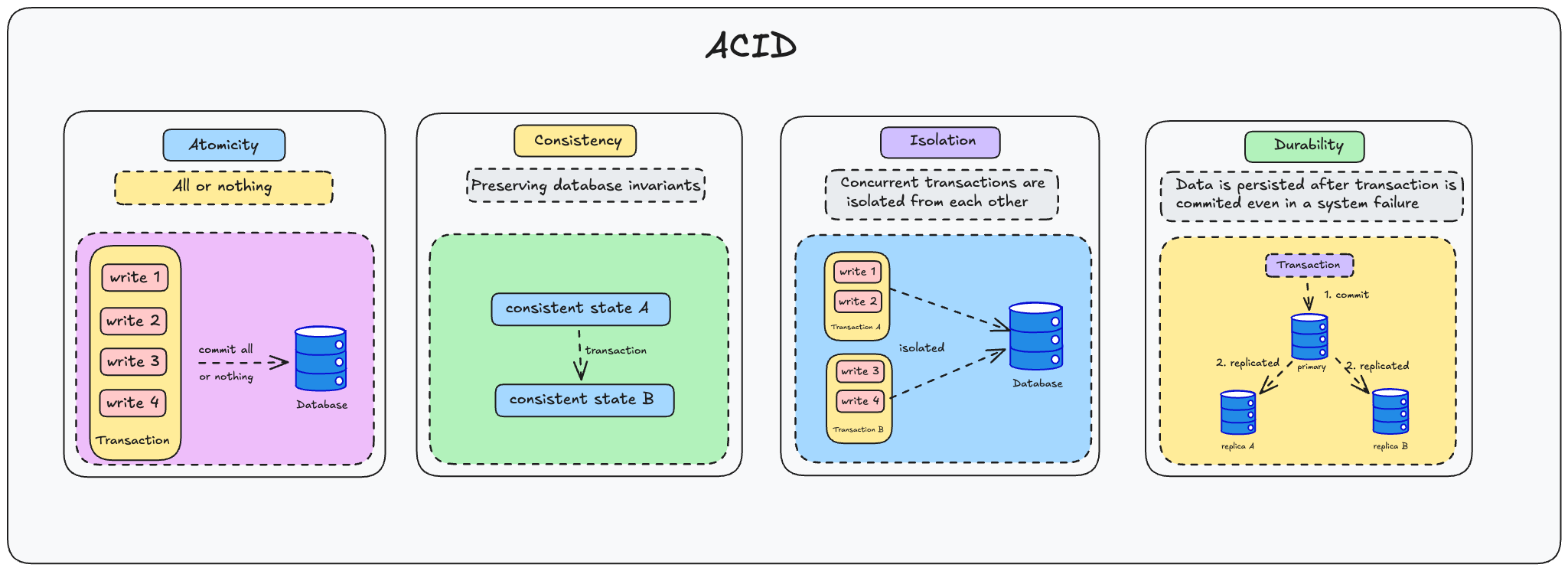
ACID là viết tắt của Atomicity (Tính nguyên tử), Consistency (Tính nhất quán), Isolation (Tính cô lập) và Durability (Tính bền vững), chúng chính là bốn trụ cột nền tảng tạo nên một transaction.
ACID được đặt ra vào năm 1983 bởi Theo Härder và Andreas Reuter trong nỗ lực thiết lập thuật ngữ chính xác cho các cơ chế khả năng chịu lỗi trong cơ sở dữ liệu.
Trong thực tế, việc triển khai ACID của các cơ sở dữ liệu có thể khác nhau
2.1. Atomicity - Được ăn cả, ngã về không
Atomicity (Tính nguyên tử) đảm bảo rằng transaction được xử lý như một đơn vị không thể chia nhỏ hơn được nữa. Hoặc là toàn bộ giao dịch sẽ được thực hiện thành công hoặc là không có gì được thực hiện cả
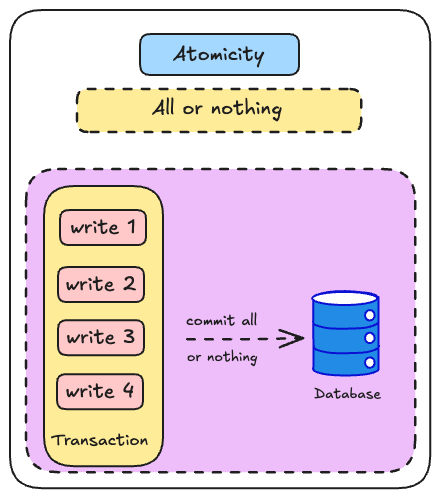
Tính nguyên tử trong ACID mô tả cách hệ thống xử lý khi xảy ra lỗi trong quá trình thực hiện một loạt thao tác ghi. Ví dụ, một client có thể gửi nhiều lệnh ghi liên tiếp, nhưng giữa chừng lại gặp sự cố như tiến trình bị treo, mất kết nối mạng, ổ đĩa đầy, hoặc vi phạm một ràng buộc toàn vẹn.
Hãy hình dung một hệ thống email: khi một email mới được gửi đến hộp thư đến, hệ thống cần thực hiện hai thao tác:
- Ghi nội dung email vào hộp thư của người nhận
- Tăng biến đếm số email chưa đọc
Nếu một lỗi xảy ra trong quá trình xử lý, chẳng hạn thao tác cập nhật biến đếm bị thất bại, thì hộp thư sẽ chứa email mới, nhưng bộ đếm không tăng. Kết quả: hệ thống rơi vào trạng thái không đồng nhất, và người dùng có thể không biết rằng họ vừa nhận được một email mới.
Với tính nguyên tử, nếu một phần của transaction thất bại (như cập nhật biến đếm), toàn bộ transaction sẽ bị hủy, và email vừa được ghi cũng sẽ bị hoàn tác. Điều này đảm bảo rằng hệ thống không bao giờ lưu lại một trạng thái không nhất quán.
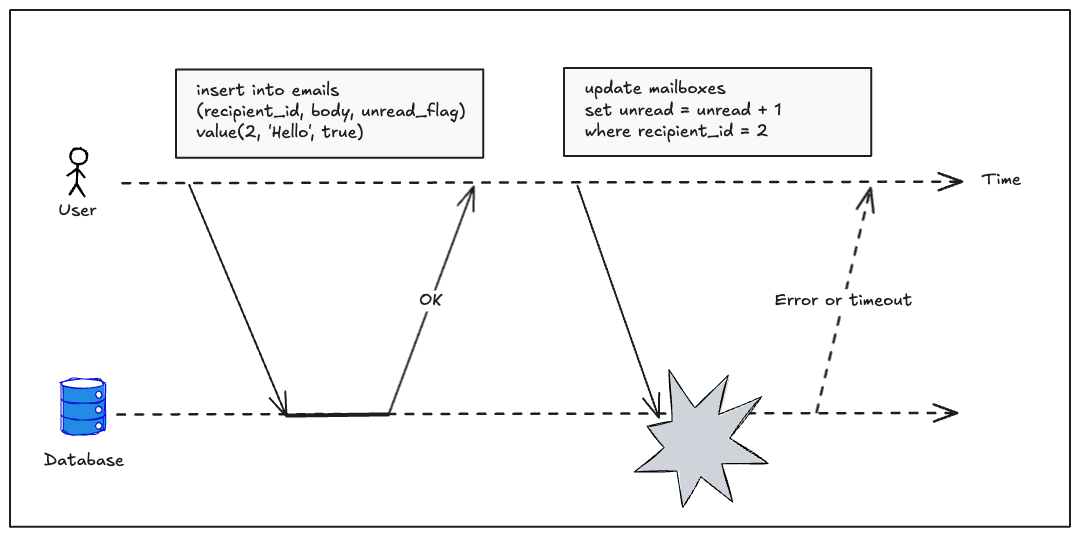
Nếu không có tính nguyên tử, việc xử lý lỗi trở nên rất phức tạp: không rõ thao tác nào đã áp dụng, thao tác nào chưa. Khi ứng dụng thử lại, có thể xảy ra tình trạng thực hiện lại một thao tác đã thành công trước đó, dẫn đến dữ liệu bị trùng lặp hoặc sai lệch.
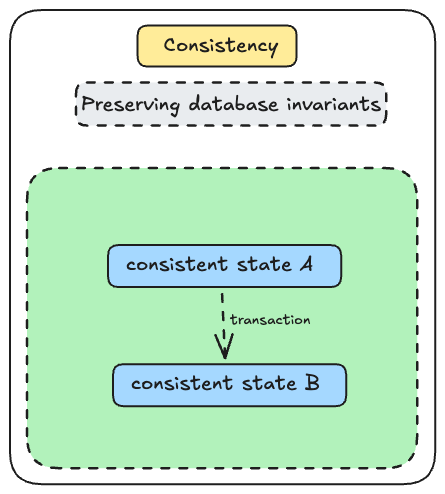
2.2. Consistency
Consistency (Tính nhất quán) trong ACID đảm bảo rằng mỗi giao dịch (transaction) sẽ đưa cơ sở dữ liệu từ một trạng thái hợp lệ sang một trạng thái hợp lệ khác. Nói cách khác, nó đảm bảo rằng dữ liệu luôn tuân thủ các ràng buộc và quy tắc được xác định trong cơ sở dữ liệu.
Hệ quản trị cơ sở dữ liệu cho phép chúng ta định nghĩa các ràng buộc (constraints) để giữ cho dữ liệu luôn hợp lệ. Một số ví dụ phổ biến:
- Số dư tài khoản không được phép âm
- No orphan mapping: Không có bản ghi nào ánh xạ tới một người đã bị xoá
- No orphan comment: Không có bình luận nào tồn tại nếu bài blog mà nó thuộc về đã bị xoá
Những ràng buộc này được thực thi thông qua cơ chế như: Constraints, Cascades, and Triggers
Tuy nhiên, ý tưởng về tính nhất quán (Consistency) thực chất lại phụ thuộc rất nhiều vào ứng dụng, chứ không chỉ nằm trong khả năng kiểm soát của cơ sở dữ liệu.
Cụ thể, mỗi ứng dụng đều có một tập hợp các bất biến (invariants) riêng, tức những điều kiện luôn phải đúng để dữ liệu được xem là hợp lệ. Chẳng hạn: “một khách hàng không thể đặt hàng nếu tài khoản bị khóa”. Cơ sở dữ liệu không thể hiểu hay tự động đảm bảo mọi bất biến đó cho bạn, chúng phải được thực thi ở cấp độ ứng dụng.
Vì vậy, trong bốn thành phần của ACID, chỉ có Atomicity, Isolation và Durability là những thuộc tính mà cơ sở dữ liệu thực sự có thể đảm bảo. Còn Consistency, theo nghĩa đúng trong ACID thực ra là một thuộc tính của ứng dụng, và ứng dụng phải dựa vào cơ sở dữ liệu để đạt được điều đó, chứ không thể phó mặc hoàn toàn cho cơ sở dữ liệu.
2.3. Isolation
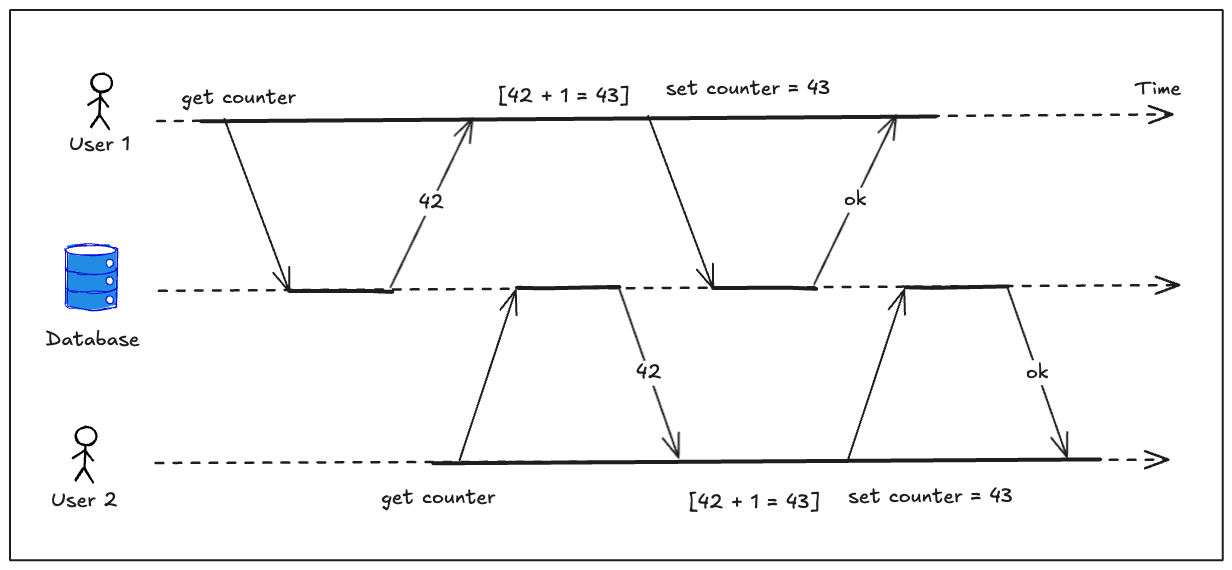
Hầu hết các cơ sở dữ liệu được nhiều client truy cập cùng một lúc. Điều đó không thành vấn đề nếu chúng đọc và ghi các phần khác nhau của cơ sở dữ liệu, nhưng nếu chúng truy cập vào cùng một bản ghi cơ sở dữ liệu, bạn có thể gặp phải các vấn đề về đồng thời (race condition). Hình ảnh bên dưới là một ví dụ đơn giản về loại vấn đề này. Giả sử bạn có hai client đồng thời tăng một bộ đếm được lưu trữ trong cơ sở dữ liệu. Mỗi client cần đọc giá trị hiện tại, cộng 1 và ghi giá trị mới trở lại (giả sử không có hoạt động tăng được tích hợp trong cơ sở dữ liệu). Trong Hình 2.3, bộ đếm đáng lẽ phải tăng từ 42 lên 44, vì hai lần tăng đã xảy ra, nhưng thực tế nó chỉ tăng lên 43 do điều kiện race.
Isolation (Tính cô lập) là một trong bốn thuộc tính quan trọng của ACID trong các hệ quản trị cơ sở dữ liệu. Nó đảm bảo rằng các giao dịch (transaction) được thực thi một cách độc lập với nhau, như thể mỗi giao dịch đang chạy một mình trên hệ thống.
Tại sao Isolation quan trọng?
Khi nhiều giao dịch được thực thi đồng thời trên cùng một cơ sở dữ liệu, có thể xảy ra các vấn đề về tính toàn vẹn dữ liệu nếu không có sự cô lập. Ví dụ:
- Dirty read: Một giao dịch đọc dữ liệu chưa được commit bởi giao dịch khác.
- Non-repeatable read: Một giao dịch đọc cùng một dữ liệu nhiều lần nhưng nhận được kết quả khác nhau do giao dịch khác đã sửa đổi dữ liệu đó.
- Phantom read: Một giao dịch đọc một tập hợp dữ liệu nhiều lần nhưng nhận được kết quả khác nhau do giao dịch khác đã thêm hoặc xóa dữ liệu trong tập hợp đó.
Các mức Isolation
Để giải quyết các vấn đề trên, các hệ quản trị cơ sở dữ liệu cung cấp các mức Isolation khác nhau:
- Read uncommitted: Mức cô lập thấp nhất, cho phép dirty read.
- Read committed: Ngăn chặn dirty read, nhưng vẫn cho phép non-repeatable read và phantom read.
- Repeatable read: Ngăn chặn dirty read và non-repeatable read, nhưng vẫn cho phép phantom read.
- Serializable: Mức cô lập cao nhất, ngăn chặn tất cả các vấn đề về tính toàn vẹn dữ liệu.
Cách thức hoạt động
Các hệ quản trị cơ sở dữ liệu sử dụng các kỹ thuật khác nhau để đảm bảo Isolation, bao gồm:
- Locking: Khóa các bản ghi hoặc bảng dữ liệu để ngăn chặn các giao dịch khác truy cập đồng thời.
- Multi-version concurrency control (MVCC): Lưu trữ nhiều phiên bản của dữ liệu, cho phép các giao dịch đọc dữ liệu từ các thời điểm khác nhau.
- Timestamp ordering: Gán timestamp cho các giao dịch và sử dụng timestamp để kiểm soát thứ tự thực thi.
Lựa chọn mức Isolation:
Việc lựa chọn mức Isolation phù hợp phụ thuộc vào yêu cầu của ứng dụng. Mức Isolation càng cao thì tính toàn vẹn dữ liệu càng được đảm bảo, nhưng hiệu năng có thể giảm.
Tóm lại:
Isolation là một thuộc tính quan trọng của ACID, đảm bảo tính toàn vẹn dữ liệu trong các hệ thống cơ sở dữ liệu đa người dùng. Việc hiểu rõ về Isolation và các mức Isolation khác nhau là điều cần thiết để thiết kế và phát triển các ứng dụng cơ sở dữ liệu đáng tin cậy.
Durability
Mục đích của một hệ thống cơ sở dữ liệu là cung cấp một nơi an toàn để dữ liệu có thể được lưu trữ mà không sợ mất mát. Durability (Tính bền vững) là lời hứa rằng một khi transaction đã được commit thành công, dữ liệu sẽ được lưu trữ bền vững trên non-volatile storage (ổ cứng, SSD) và có thể được khôi phục ngay cả khi hệ thống gặp sự cố như mất điện, crash ứng dụng, hoặc restart hệ điều hành.
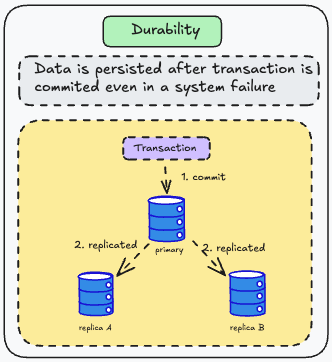
Thực tế, tính bền vững hoàn hảo không tồn tại: nếu tất cả các ổ cứng của bạn và tất cả các bản sao lưu của bạn bị phá hủy cùng một lúc, thì rõ ràng là không có gì mà cơ sở dữ liệu của bạn có thể làm để cứu bạn.
3. Weak Isolation Levels: Chọn hiệu năng hay tính đúng đắn?
Nếu hai transaction không truy cập cùng một dữ liệu, chúng có thể chạy song song an toàn vì không phụ thuộc lẫn nhau. Vấn đề concurrency (race condition) chỉ xuất hiện khi một transaction đọc dữ liệu đang được transaction khác sửa, hoặc khi cả hai cùng lúc cố gắng sửa cùng một dữ liệu.
Những lỗi concurrency rất khó phát hiện bằng kiểm thử, vì chúng chỉ xảy ra khi có sự trùng hợp về timing cụ thể giữa các thread/process. Tình huống này có thể xuất hiện cực kỳ hiếm và gần như không thể tái hiện chính xác. Concurrency cũng khó để suy luận, đặc biệt trong các ứng dụng lớn, nơi bạn không thể biết chắc đoạn code nào khác đang truy cập vào cùng dữ liệu. Phát triển ứng dụng vốn đã phức tạp khi chỉ có một người dùng; khi có nhiều người dùng đồng thời, mọi thứ khó hơn nhiều vì bất kỳ dữ liệu nào cũng có thể thay đổi ngoài ý muốn vào bất kỳ thời điểm nào.
Chính vì vậy, cơ sở dữ liệu từ lâu đã cố gắng “che” vấn đề concurrency khỏi lập trình viên bằng cách cung cấp transaction isolation. Về lý thuyết, isolation cho phép bạn giả vờ như không hề có concurrency: serializable isolation đảm bảo kết quả giống như khi các transaction chạy tuần tự (từng cái một, không song song).
Nhưng thực tế không đơn giản như vậy. Serializable isolation có giá phải trả về hiệu năng, và nhiều hệ quản trị cơ sở dữ liệu không muốn gánh chi phí này. Thay vào đó, chúng thường sử dụng weak isolation levels — mức cô lập yếu hơn, chỉ bảo vệ khỏi một số vấn đề concurrency nhất định, nhưng không phải tất cả. Điều này vừa khó hiểu vừa dễ gây ra các lỗi tinh vi, nhưng vẫn được dùng rộng rãi.
Những lỗi concurrency do weak isolation không chỉ là lý thuyết. Chúng đã gây ra tổn thất tài chính lớn, bị kiểm toán điều tra, và làm hỏng dữ liệu khách hàng. Nhiều người vẫn khuyên “Dùng ACID database khi xử lý dữ liệu tài chính!”, nhưng thực tế ngay cả nhiều hệ quản trị cơ sở dữ liệu quan hệ phổ biến (thường được xem là “ACID”) cũng dùng weak isolation, nên không nhất thiết ngăn được những lỗi này.
Do đó, thay vì mù quáng tin vào công cụ, chúng ta cần hiểu rõ các loại vấn đề concurrency tồn tại và cách phòng tránh chúng. Từ đó, mới có thể xây dựng ứng dụng đáng tin cậy, chính xác với những công cụ hiện có.
Trong phần này, chúng ta sẽ tìm hiểu một số weak (nonserializable) isolation levels được dùng trong thực tế, phân tích chi tiết những loại race condition có thể và không thể xảy ra, để bạn có thể chọn mức phù hợp với ứng dụng của mình. Sau đó, chúng ta sẽ đi sâu vào serializability.
3.1. Read Committed
Mức độ transaction isolation cơ bản nhất là read committed. Nó đưa ra hai đảm bảo:
- Khi đọc từ cơ sở dữ liệu, bạn sẽ chỉ thấy dữ liệu đã được commit (no dirty read).
- Khi ghi vào cơ sở dữ liệu, bạn sẽ chỉ ghi đè dữ liệu đã được commit (no dirty write).
No dirty reads
Giả sử một transaction đã ghi một số dữ liệu vào database, nhưng transaction đó vẫn chưa commit hoặc abort. Liệu một transaction khác có thể nhìn thấy dữ liệu chưa được commit này không?
Nếu câu trả lời là “có”, thì đó được gọi là dirty read.
Hậu quả của việc đọc dữ liệu chưa được commit này là:
- Nếu một transaction cần cập nhật nhiều đối tượng, dirty read có thể khiến transaction khác thấy một phần thay đổi nhưng không thấy phần còn lại. Ví dụ, trong Hình ảnh bên dưới minh hoạ trường hợp người dùng thấy email mới chưa đọc nhưng lại không thấy bộ đếm số lượng thư được cập nhật. Đây chính là dirty read trên dữ liệu email. Việc nhìn thấy cơ sở dữ liệu ở trạng thái cập nhật dở dang không chỉ gây bối rối cho người dùng mà còn dễ khiến các transaction khác ra quyết định sai.
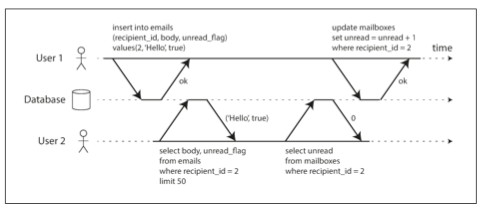
- Nếu một transaction bị rollback, mọi thay đổi nó đã ghi sẽ bị xóa bỏ (như trong Hình 2.1). Nếu cơ sở dữ liệu cho phép dirty read, nghĩa là có transaction đã “thấy” dữ liệu mà sau đó bị xóa mất — dữ liệu này thực chất chưa bao giờ tồn tại chính thức trong hệ thống. Điều này khiến việc suy luận và đảm bảo tính đúng đắn trở nên cực kỳ rối rắm.
Với mức Read Committed, dirty read bị ngăn chặn hoàn toàn. Nghĩa là mọi thay đổi của một transaction chỉ được nhìn thấy bởi các transaction khác sau khi nó commit, và khi commit, tất cả thay đổi sẽ hiển thị cùng lúc.
No dirty writes
Với những lập trình viên đã đi làm vài năm, chắc hẳn việc hai transaction đồng thời cùng cập nhật một đối tượng trong database đã không còn là vấn đề xa lạ.
Dirty write là hiện tượng xảy ra khi một giao dịch ghi đè lên dữ liệu chưa được commit của một giao dịch khác.
Chúng ta hãy cùng phân tích ví dụ sau để hiểu về dirty write và những ảnh hưởng của nó đến tính đúng đắn của dữ liệu:
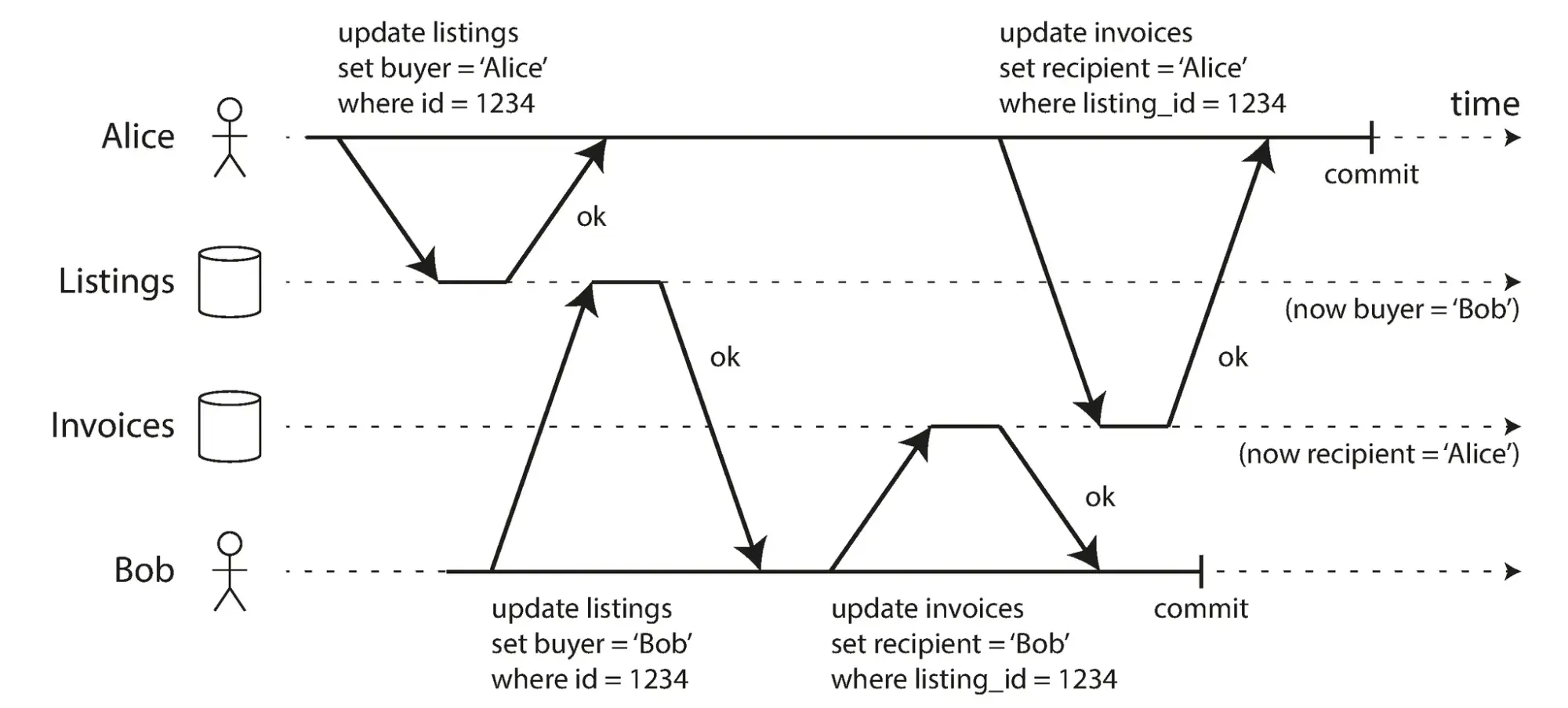
Giả sử trên một website mua bán xe cũ, cả Alice và Bob cùng lúc muốn mua cùng một chiếc xe.
Quá trình mua xe cần 2 thao tác ghi vào cơ sở dữ liệu:
- Cập nhật thông tin chiếc xe trên trang web để thể hiện người mua.
- Gửi hóa đơn bán xe cho người mua.
Trong tình huống xấu, Bob có thể "thắng" ở bước cập nhật thông tin xe (nên xe được gán cho Bob), nhưng Alice lại "thắng" ở bước cập nhật hóa đơn (nên hóa đơn lại gửi cho Alice).
Kết quả là một mớ hỗn loạn: Bob có xe, Alice có hóa đơn :v
Với mức isolation Read Committed, cơ sở dữ liệu sẽ ngăn chặn dirty write, tức là nếu Alice đã cập nhật thông tin xe thành công nhưng transaction chưa commit hoặc rollback thì Bob không thể update thông tin xe và sẽ không còn tình trạng một người nhận xe, một người nhận hoá đơn nữa.
Implementing Read Committed
Read committed là một trong những isolation level phổ biến nhất, và là cấu hình mặc định ở nhiều hệ quản trị cơ sở dữ liệu như Oracle 11g, PostgreSQL, SQL Server 2012, MemSQL, v.v.
Vậy cơ sở dữ liệu đã làm gì phía sau để đạt được isolation level này?
Trước tiên, để ngăn dirty write, hầu hết các hệ thống sử dụng row-level lock. Khi một transaction muốn sửa đổi một đối tượng (một row trong bảng hoặc một document), nó phải acquire lock trên đối tượng đó. Lock này sẽ được giữ cho đến khi transaction commit hoặc abort. Tại bất kỳ thời điểm nào, chỉ duy nhất một transaction có thể giữ lock trên một đối tượng. Nếu một transaction khác cũng muốn ghi lên cùng đối tượng đó, nó buộc phải chờ cho đến khi transaction đang giữ lock hoàn tất.
Điểm quan trọng: cơ chế lock này diễn ra hoàn toàn tự động khi cơ sở dữ liệu hoạt động ở read committed hoặc isolation level cao hơn.
Tiếp theo, để ngăn dirty read, có một cách tưởng chừng hợp lý: yêu cầu transaction muốn đọc một đối tượng cũng phải tạm thời acquire lock, sau đó release ngay sau khi đọc. Điều này đảm bảo rằng khi một đối tượng đang ở trạng thái chưa commit, sẽ không có transaction nào đọc được giá trị tạm thời đó.
Nhưng giải pháp này không thực tế. Vì nếu một transaction ghi dữ liệu kéo dài, nó sẽ khiến hàng loạt transaction chỉ đọc phải chờ đợi để lấy khoá, gây ra độ trễ dây chuyền sang nhiều phần khác của hệ thống. Chỉ một điểm nghẽn nhỏ cũng có thể kéo chậm toàn bộ ứng dụng.
Do đó, hầu hết các cơ sở dữ liệu tránh dirty read bằng cách giữ cả giá trị cũ và giá trị mới. Khi một transaction ghi dữ liệu, hệ thống sẽ lưu lại:
- Giá trị cũ đã commit (old committed value) được lưu trong trong data files hoặc tablespaces (ổ đĩa, đảm bảo bền vững).
- Giá trị mới do transaction hiện tại thiết lập (uncommitted value), được lưu tại buffer cache (RAM) + redo/undo log.
Khi transaction này vẫn đang diễn ra, bất kỳ transaction nào khác muốn đọc dữ liệu đó sẽ được trả về giá trị cũ. Chỉ khi transaction ghi commit, các transaction khác mới bắt đầu đọc giá trị mới.
Cơ chế này cho phép hệ thống đọc không chặn ghi và ghi không phá vỡ dữ liệu đọc, đảm bảo tính toàn vẹn dữ liệu mà vẫn duy trì hiệu năng cao — đúng tinh thần của read committed.
3.2. Repeatable Read và Snapshot Isolation
Nếu chỉ nhìn qua, bạn có thể dễ dàng nghĩ rằng mức isolation Read Committed đã đáp ứng đầy đủ mọi thứ mà một giao dịch cần:
- Cho phép abort (đảm bảo tính atomicity).
- Ngăn đọc dữ liệu chưa commit.
- Ngăn việc các thao tác ghi đồng thời bị trộn lẫn vào nhau (dirty write).
Quả thật, đây đều là những tính năng hữu ích — mạnh hơn rất nhiều so với một hệ thống không hề hỗ trợ transaction.
Tuy nhiên, Read Committed vẫn chưa đủ an toàn. Vẫn còn nhiều kiểu bug liên quan đến lập trình đồng thời có thể xảy ra ở mức isolation này.
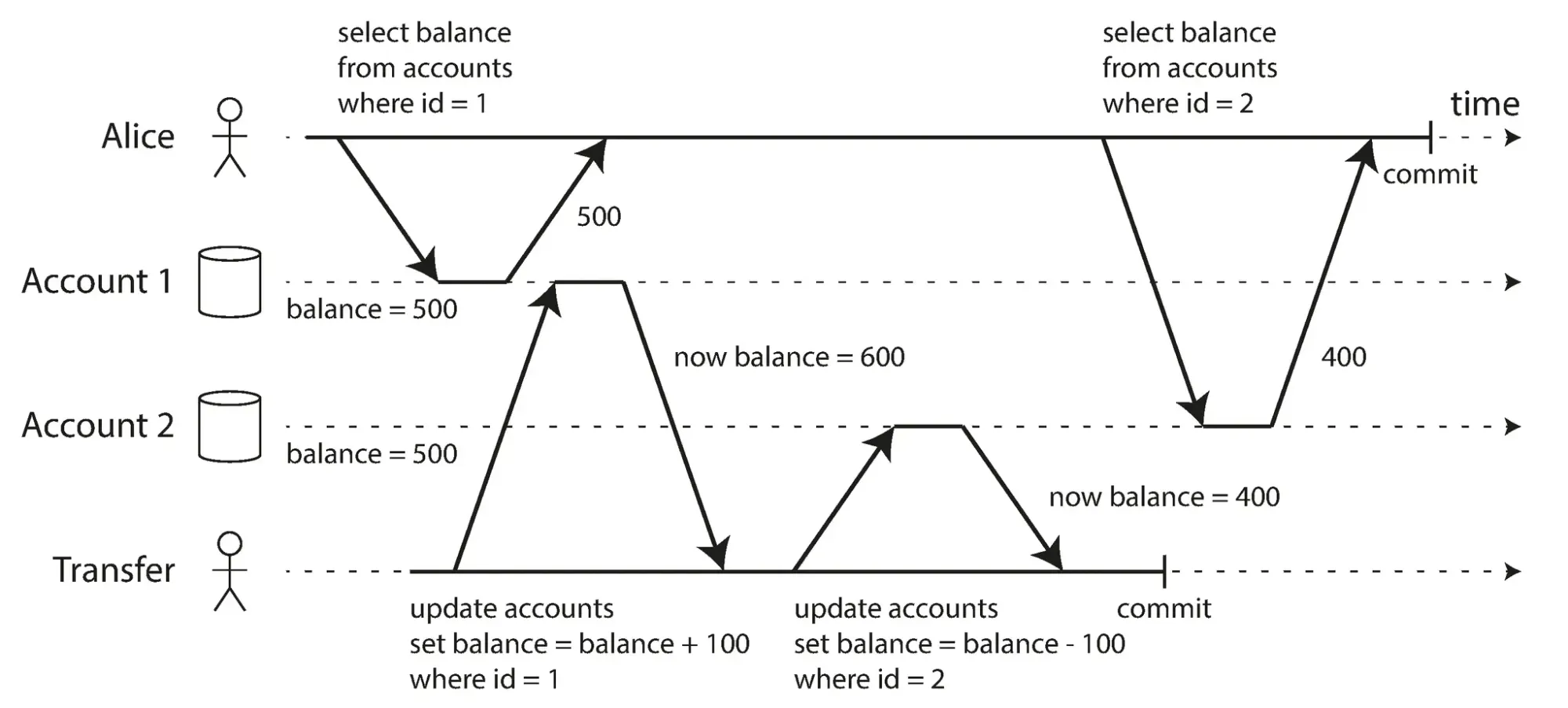
Ví dụ, hãy xem kịch bản sau:
Alice có 1.000 USD trong tài khoản tiết kiệm tại ngân hàng, chia đều vào 2 tài khoản con: mỗi tài khoản 500 USD.
Bây giờ, có một giao dịch đang chuyển 100 USD từ tài khoản A sang tài khoản B.
Nếu Alice không may truy vấn danh sách số dư ngay trong lúc giao dịch kia đang chạy, cô ấy có thể nhìn thấy:
- Tài khoản A: đã trừ 100 USD → còn 400 USD (bước debit đã xong).
- Tài khoản B: chưa cộng thêm 100 USD → vẫn 500 USD (bước credit chưa thực hiện).
Tổng số dư Alice nhìn thấy lúc này chỉ còn 900 USD — mặc dù thực tế tiền của cô ấy vẫn là 1.000 USD.
Hiện tượng này gọi là Read Skew (non-repeatable read): dữ liệu được đọc từ nhiều bản ghi khác nhau nhưng lại ở những thời điểm khác nhau, dẫn đến trạng thái không nhất quán.
Trong trường hợp của Alice, đây không phải là vấn đề nghiêm trọng, vì cô sẽ thấy số dư nhất quán nếu tải lại trang web ngân hàng vài giây sau. Tuy nhiên, có những tình huống không thể chấp nhận sự không nhất quán tạm thời như vậy:
- Sao lưu (Backups): Sao lưu đòi hỏi phải tạo bản sao toàn bộ cơ sở dữ liệu, có thể mất hàng giờ với cơ sở dữ liệu lớn. Trong thời gian sao lưu, các ghi mới vẫn tiếp tục diễn ra, dẫn đến một số phần của bản sao lưu chứa dữ liệu cũ, trong khi phần khác chứa dữ liệu mới. Nếu cần khôi phục từ bản sao lưu này, sự không nhất quán (như tiền “biến mất”) sẽ trở thành vĩnh viễn.
- Truy vấn phân tích và kiểm tra toàn vẹn dữ liệu: Đôi khi bạn muốn chạy một truy vấn quét qua phần lớn dữ liệu. Các truy vấn này có thể trả về kết quả vô nghĩa nếu chúng đọc các phần của cơ sở dữ liệu ở những thời điểm khác nhau.
Snapshot isolation là giải pháp phổ biến nhất cho vấn đề này. Ý tưởng là mỗi giao dịch đọc từ một ảnh chụp nhất quán (consistent snapshot) của cơ sở dữ liệu, nghĩa là giao dịch sẽ thấy toàn bộ dữ liệu đã được commit trong cơ sở dữ liệu tại thời điểm bắt đầu giao dịch. Dù dữ liệu có bị thay đổi sau đó bởi giao dịch khác, mỗi giao dịch vẫn chỉ thấy dữ liệu cũ từ thời điểm ban đầu đó.
Implementing snapshot isolation
Việc "chụp ảnh" này nghe có vẻ là một thao tác cực kỳ tốn kém, có thể sẽ làm giảm hiệu năng nghiêm trọng của cơ sở dữ liệu. Tưởng tượng việc phải sao chép toàn bộ dữ liệu cho mỗi giao dịch! May mắn thay, các cơ sở dữ liệu hiện đại đã tìm ra cách triển khai snapshot isolation một cách hiệu quả thông qua kỹ thuật Multi-Version Concurrency Control (MVCC).
MVCC hoạt động dựa trên nguyên tắc đơn giản: Copy-on-write thay vì copy-everything, thay vì ghi đè lên dữ liệu cũ, hệ thống sẽ tạo ra phiên bản mới của mỗi đối tượng. Điều này có nghĩa là cơ sở dữ liệu có thể duy trì nhiều phiên bản của cùng một đối tượng dữ liệu, mỗi phiên bản được đánh dấu với transaction ID đã tạo ra nó.
Hãy xem cách MVCC hoạt động trong thực tế:
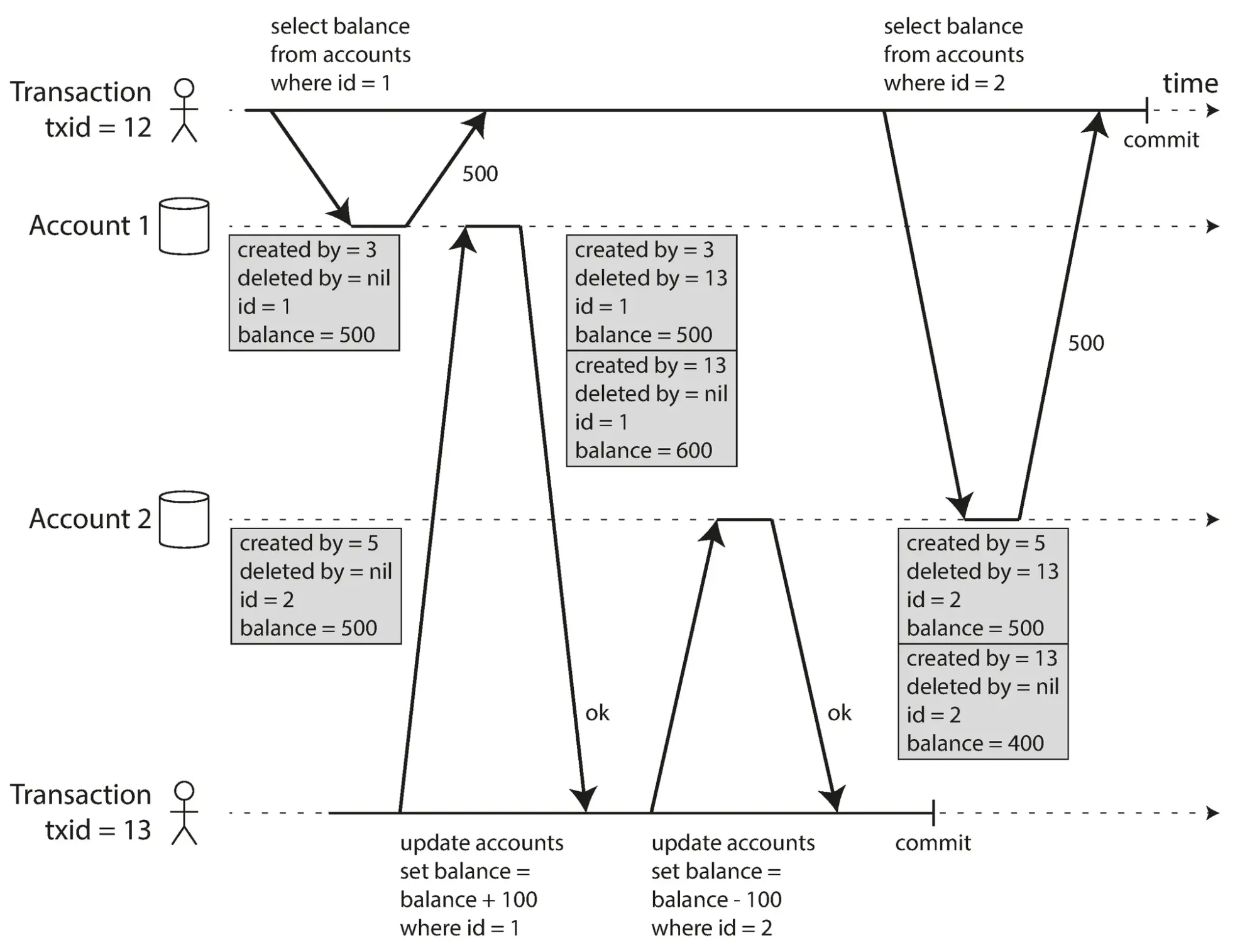
Mỗi hàng trong bảng có một trường created_by, chứa ID của giao dịch đã chèn hàng này vào bảng. Ngoài ra, mỗi hàng có một trường deleted_by, ban đầu trống. Nếu một giao dịch xóa một hàng, hàng đó không thực sự bị xóa khỏi cơ sở dữ liệu, nhưng nó được đánh dấu để xóa bằng cách đặt trường deleted_by thành ID của giao dịch đã yêu cầu xóa. Tại một số thời điểm sau đó, khi chắc chắn rằng không có giao dịch nào có thể truy cập dữ liệu đã xóa nữa, một quy trình thu gom rác trong cơ sở dữ liệu sẽ xóa bất kỳ hàng nào được đánh dấu để xóa và giải phóng không gian của chúng.
Lợi ích của cách tiếp cận này:
- Đọc snapshot nhất quán: Các giao dịch có thể đọc một snapshot nhất quán của cơ sở dữ liệu bằng cách chỉ xem xét các hàng có
created_bynhỏ hơn ID giao dịch của nó và không códeleted_byhoặc códeleted_bylớn hơn ID giao dịch của nó. - Hiệu năng: Tránh xung đột giữa đọc và ghi, vì việc đọc không cần khóa.
- Khả năng mở rộng: Phù hợp với các hệ thống phân tán.
Visibility rules for observing a consistent snapshot
- Bỏ qua các thay đổi từ các giao dịch đang thực thi: Khi một giao dịch bắt đầu, nó sẽ tạo một "snapshot" của cơ sở dữ liệu tại thời điểm đó. Bất kỳ thay đổi nào do các giao dịch khác đang thực thi (chưa commit) sẽ bị bỏ qua, ngay cả khi các giao dịch đó sau này được commit.
- Bỏ qua các thay đổi từ các giao dịch bị hủy: Các thay đổi do các giao dịch bị hủy (abort) sẽ không bao giờ được hiển thị.
- Bỏ qua các thay đổi từ các giao dịch mới hơn: Các thay đổi do các giao dịch bắt đầu sau giao dịch hiện tại sẽ bị bỏ qua, bất kể chúng đã được commit hay chưa.
- Hiển thị tất cả các thay đổi khác: Các thay đổi đáp ứng các điều kiện trên sẽ được hiển thị cho giao dịch.
Các quy tắc này áp dụng cho cả việc tạo và xóa đối tượng. Trong ví dụ trên, khi giao dịch 12 đọc từ tài khoản 2, nó thấy số dư là 500 đô la vì việc xóa số dư 500 đô la được thực hiện bởi giao dịch 13 (theo quy tắc 3, giao dịch 12 không thể thấy việc xóa được thực hiện bởi giao dịch 13) và việc tạo số dư 400 đô la vẫn chưa hiển thị (theo cùng một quy tắc).
Nói cách khác, một đối tượng hiển thị nếu cả hai điều kiện sau đều đúng:
- Tại thời điểm giao dịch của người đọc bắt đầu, giao dịch đã tạo đối tượng đã được commit.
- Đối tượng không được đánh dấu để xóa hoặc nếu có, giao dịch đã yêu cầu xóa vẫn chưa được commit tại thời điểm giao dịch của người đọc bắt đầu.
Index và MVCC
Một thách thức thú vị của MVCC là việc xử lý index. Có hai cách tiếp cận chính:
Cách 1: Index trỏ đến tất cả phiên bản Index chứa tất cả các phiên bản của một đối tượng, và việc lọc phiên bản phù hợp được thực hiện khi đọc dữ liệu. Đây là cách PostgreSQL làm.
Cách 2: Index trỏ đến phiên bản mới nhất
Index chỉ trỏ đến phiên bản mới nhất, và hệ thống duy trì "version chain" để truy cập các phiên bản cũ khi cần. MySQL với InnoDB engine sử dụng phương pháp này.
Câu hỏi đặt ra là trade-offs của 2 phương pháp tiếp cận này là gì? Hãy thử trả lời và comment phía dưới cho mình biết nhé 😉
3.3. Preventing Lost Updates
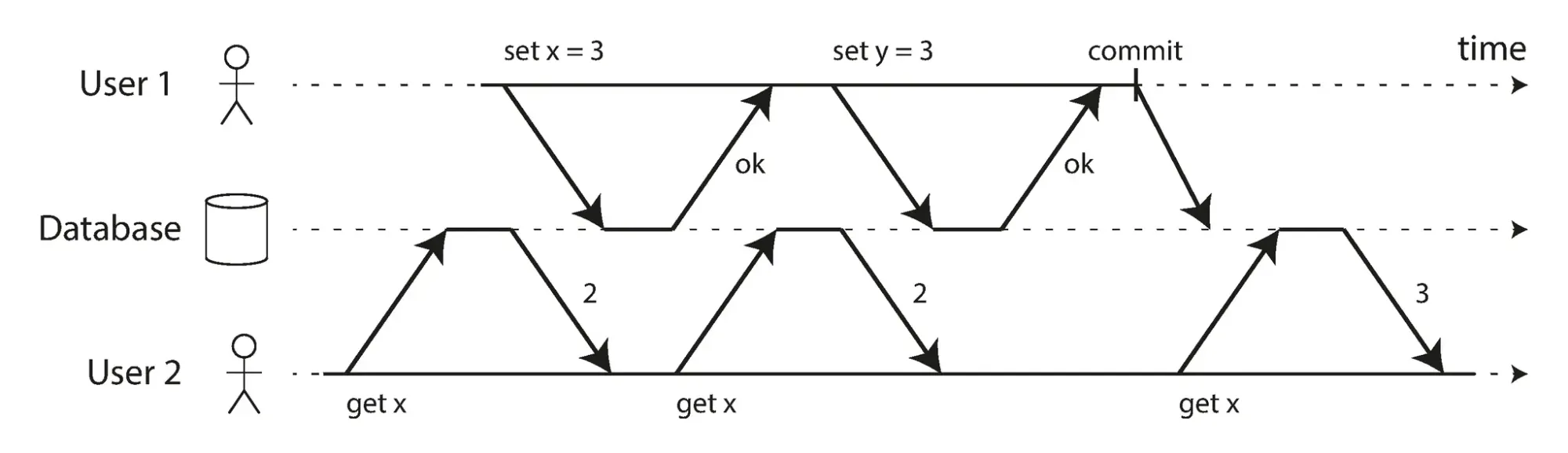
Các mức cô lập read committed và snapshot isolation mà chúng ta đã thảo luận cho đến nay chủ yếu nói về các đảm bảo về những gì mà một giao dịch chỉ đọc có thể thấy khi có các ghi đồng thời. Chúng ta hầu như đã bỏ qua vấn đề hai giao dịch ghi đồng thời, và ta mới chỉ đả động đến vấn đề này ở phần dirty write. Nhưng thực tế, có một số loại xung đột thú vị khác có thể xảy ra giữa các giao dịch ghi đồng thời mà ngay cả các cơ chế mà ta đề cập như snapshot isolation hay read committed không thể ngăn chặn được. Nổi tiếng nhất trong số này là vấn đề mất cập nhật (lost update problem), được minh họa trong hình x.x với ví dụ về hai lần tăng bộ đếm đồng thời.
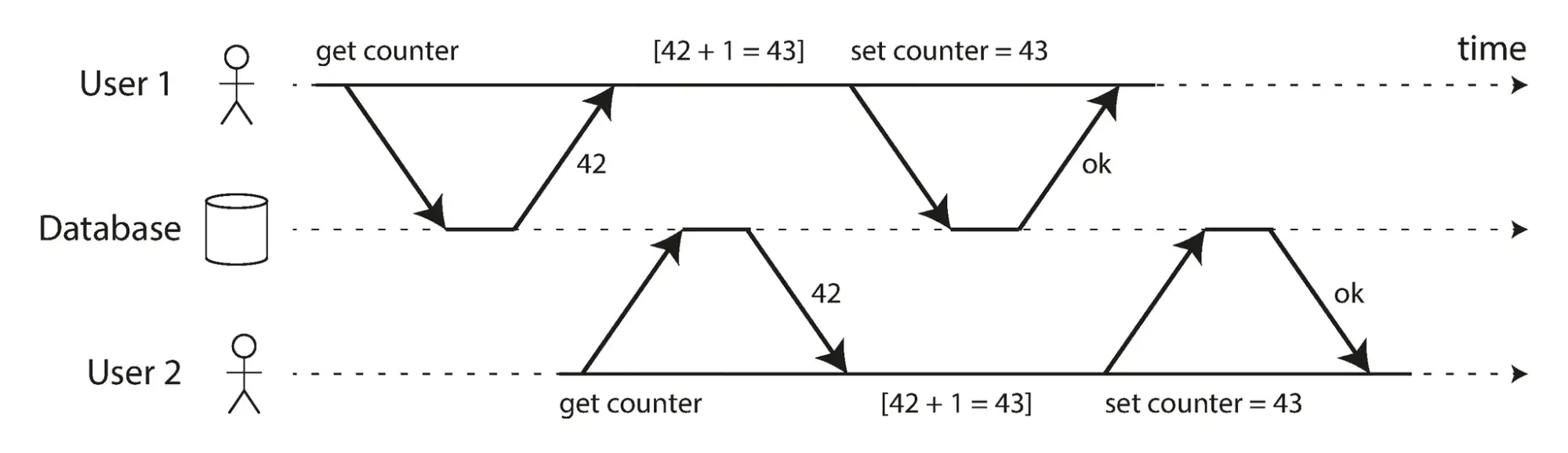
Nếu bạn muốn, có thể chạy SQL dưới đây để thử nghiệm
-- =============================================================================
-- LOST UPDATE PROBLEM - SQL SIMULATION
-- =============================================================================
-- Setup: Tạo bảng counter với giá trị ban đầu
CREATE TABLE counters (
id INT PRIMARY KEY,
value INT NOT NULL
);
INSERT INTO counters (id, value) VALUES (1, 42);
-- =============================================================================
-- SCENARIO: Hai transactions đồng thời increment counter
-- Initial counter value: 42
-- Expected final value: 44 (42 + 1 + 1)
-- Actual final value: 43 (LOST UPDATE!)
-- =============================================================================
-- Timeline simulation using transaction isolation level READ COMMITTED
-- hoặc SNAPSHOT ISOLATION
-- ┌─────────────────────────────────────────────────────────────────┐
-- │ USER 1 (Transaction A) │
-- └─────────────────────────────────────────────────────────────────┘
-- T1: User 1 bắt đầu transaction
BEGIN; -- Transaction A starts
-- T2: User 1 đọc giá trị hiện tại của counter
SELECT value FROM counters WHERE id = 1;
-- Result: 42
-- T3: User 1 tính toán giá trị mới (trong application code)
-- new_value = 42 + 1 = 43
-- ... User 1 đang xử lý logic khác trong application ...
-- ┌─────────────────────────────────────────────────────────────────┐
-- │ USER 2 (Transaction B) │
-- └─────────────────────────────────────────────────────────────────┘
-- Trong khi đó, User 2 cũng bắt đầu transaction
-- (Chạy trong session/connection khác)
BEGIN; -- Transaction B starts
-- T4: User 2 đọc cùng giá trị counter (vì Transaction A chưa commit)
SELECT value FROM counters WHERE id = 1;
-- Result: 42 (same as User 1 saw!)
-- T5: User 2 tính toán giá trị mới
-- new_value = 42 + 1 = 43 (same calculation!)
-- ┌─────────────────────────────────────────────────────────────────┐
-- │ RACE CONDITION │
-- └─────────────────────────────────────────────────────────────────┘
-- T6: User 1 ghi giá trị đã tính toán
UPDATE counters SET value = 43 WHERE id = 1;
-- Counter is now 43
COMMIT; -- Transaction A commits successfully
-- T7: User 2 cũng ghi giá trị đã tính toán (dựa trên stale data!)
UPDATE counters SET value = 43 WHERE id = 1;
-- Counter is still 43 (overwrites User 1's change!)
COMMIT; -- Transaction B commits successfully
-- ┌─────────────────────────────────────────────────────────────────┐
-- │ RESULT │
-- └─────────────────────────────────────────────────────────────────┘
-- Kiểm tra kết quả cuối cùng
SELECT value FROM counters WHERE id = 1;
-- Result: 43
-- PROBLEM: User 1's increment is LOST!
-- Expected: 44 (42 + 1 + 1)
-- Actual: 43 (only one increment was applied)
Vấn đề mất cập nhật có thể xảy ra nếu một ứng dụng đọc một số giá trị từ cơ sở dữ liệu, sửa đổi nó và ghi lại giá trị đã sửa đổi (chu kỳ đọc-sửa đổi-ghi). Nếu hai giao dịch thực hiện việc này đồng thời, một trong các sửa đổi có thể bị mất, bởi vì ghi thứ hai không bao gồm sửa đổi đầu tiên. (Đôi khi chúng ta nói rằng ghi sau sẽ ghi đè lên ghi trước.) Mô hình này xảy ra trong các tình huống khác nhau:
- Tăng bộ đếm hoặc cập nhật số dư tài khoản (yêu cầu đọc giá trị hiện tại, tính toán giá trị mới và ghi lại giá trị đã cập nhật)
- Thực hiện thay đổi cục bộ đối với một giá trị phức tạp, ví dụ: thêm một phần tử vào danh sách trong tài liệu JSON (yêu cầu phân tích cú pháp tài liệu, thực hiện thay đổi và ghi lại tài liệu đã sửa đổi)
- Hai người dùng chỉnh sửa trang wiki cùng một lúc, trong đó mỗi người dùng lưu các thay đổi của họ bằng cách gửi toàn bộ nội dung trang đến máy chủ, ghi đè lên bất cứ thứ gì hiện có trong cơ sở dữ liệu
Đương nhiên có vấn đề sẽ có giải pháp hoặc … nhiều giải pháp :v
Atomic write operations (UPDATE … WHERE)
Atomic operation: cho phép ứng dụng sửa đổi dữ liệu mà không cần phải thực hiện chu trình đọc-sửa đổi-ghi (read-modify-write) phức tạp.
Ví dụ:
UPDATE counters SET value = value + 1 WHERE key = 'foo';
Cách Database thực hiện Atomicity
Các atomic operation thường được triển khai bằng cách sử dụng khóa độc quyền (exclusive locking) trên đối tượng khi nó được đọc, cho phép chỉ một thread/transaction duy nhất truy cập tài nguyên tại một thời điểm: Ví dụ:
Exclusive Locking:
-- Internally, database might do:
LOCK TABLE counters IN EXCLUSIVE MODE;
SELECT value FROM counters WHERE id = 1; -- value = 42
UPDATE counters SET value = 43 WHERE id = 1;
UNLOCK TABLE counters;
-- All in one atomic operation
Single-threaded Execution:
-- Redis approach: All operations on same key execute sequentially
Thread 1: INCR counter → 42 → 43
Thread 2: INCR counter → 43 → 44 (waits for Thread 1)
Hạn chế:
Không phải tất cả các hoạt động ghi đều có thể dễ dàng được biểu diễn dưới dạng atomic operation, nhất là trong các trường hợp business logic phức tạp, bạn cần phải đọc dữ liệu, xử lý và update nhiều bản ghi hoặc nhiều bảng. Trong những trường hợp như vậy, ta cần chủ động kiểm soát khoá các bản ghi liên quan bằng cách sử dụng Explicit Locking.
Explicit locking (SELECT … FOR UPDATE)
- Đây là cơ chế khóa tường minh, do bạn chủ động yêu cầu database đặt khóa trên các bản ghi khi đọc dữ liệu.
- Bản ghi trả về sẽ bị đặt exclusive lock (ngăn ghi/đọc xung đột) cho đến khi transaction kết thúc.
Cú pháp thường dùng:
SELECT ... FROM ... WHERE ... FOR UPDATE;
3.4. Write Skew and Phantoms
Trong các phần trước, chúng ta đã thấy dirty writes và lost updates, hai loại race condition xảy ra khi các transaction đồng thời cố gắng ghi vào cùng một đối tượng. Để tránh hỏng dữ liệu, các race condition này cần được ngăn chặn.
Tuy nhiên, đó không phải là tất cả các race condition tiềm ẩn. Write skew và phantom read là những ví dụ tinh vi hơn về xung đột có thể xảy ra giữa các ghi đồng thời.
Write Skew là gì?
💡Write Skew xảy ra khi hai giao dịch đồng thời đọc và ghi vào các đối tượng khác nhau, nhưng các đối tượng này phải tuân theo một quy tắc nghiệp vụ chung. Do mỗi giao dịch nhìn thấy một snapshot nhất quán của cơ sở dữ liệu tại thời điểm nó bắt đầu, nên chúng không nhận thức được các thay đổi mà giao dịch kia đang thực hiện. Điều này có thể dẫn đến việc vi phạm ràng buộc và làm hỏng dữ liệu.
Ví dụ trong hình:
- Cả Alice và Bob đều kiểm tra xem có ít nhất hai bác sĩ đang trực không. Do sử dụng Snapshot Isolation, cả hai đều thấy có hai bác sĩ đang trực (bao gồm chính họ).
- Cả hai đều quyết định nghỉ, vì nghĩ rằng vẫn còn một bác sĩ khác đang trực.
- Kết quả là cả hai bác sĩ đều nghỉ, vi phạm ràng buộc phải có ít nhất một bác sĩ trực.
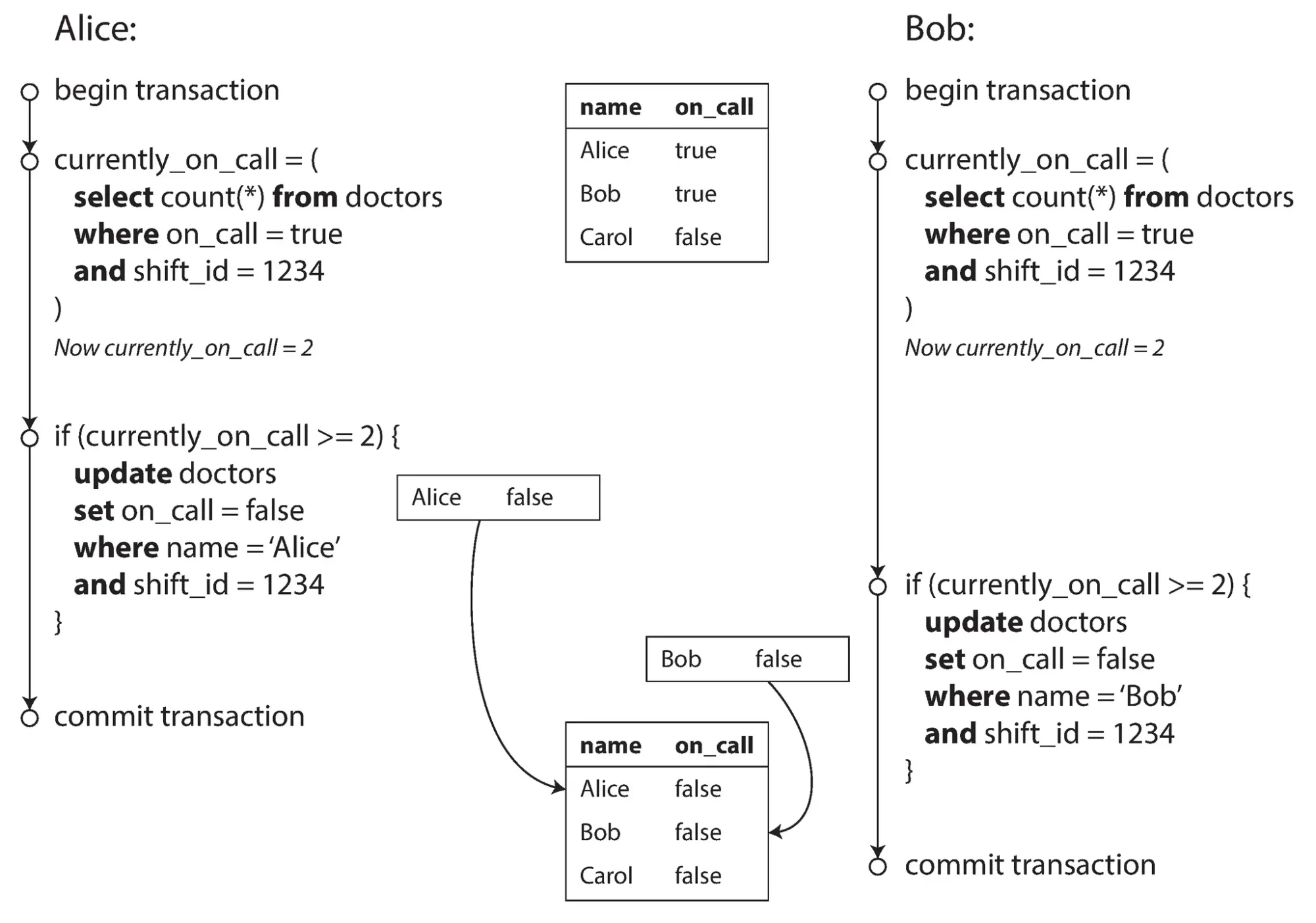
Write skew không phải là dirty write hay lost update, vì hai transaction đang cập nhật các đối tượng khác nhau. Tuy nhiên, nó vẫn là một race condition: nếu hai transaction chạy lần lượt, transaction thứ hai sẽ bị ngăn không cho bác sĩ nghỉ.
Đến đây thì có thể bạn sẽ hơi rối rồi, sao mà lắm race condition vậy. Write skew khác gì dirty write hay lost update? Ở trên ta đã đề cập đến read skew, liệu chúng có gì liên hệ với nhau không?
Câu trả lời là: tất cả những cái này đều là anomaly (hiện tượng bất thường) trong xử lý đồng thời, nhưng mức độ và bản chất thì khác nhau:
- Dirty write: hai transaction cùng lúc ghi đè lên cùng một dữ liệu, transaction A chưa kịp commit thì transaction B ghi đè lên → kết quả cuối cùng có thể mất mát hoặc không nhất quán. Đây là anomaly “thô sơ” nhất, đa số DB đều chặn ngay từ isolation level thấp.
- Lost update: hai transaction cùng đọc một giá trị, rồi cả hai cùng update dựa trên giá trị cũ đó. Update của một transaction sẽ đè mất update của transaction kia. Có thể tránh bằng atomic operation, compare-and-set, hoặc lock.
- Read skew (hay non-repeatable read): một transaction đọc cùng một dữ liệu nhiều lần nhưng lại thấy kết quả khác nhau, vì transaction khác đã commit xen vào giữa. Điều này làm cho ứng dụng khó reasoning về tính nhất quán.
- Write skew: nâng cấp hơn lost update. Hai transaction đọc cùng một tập dữ liệu và mỗi bên cập nhật một phần khác nhau, nhưng kết quả kết hợp lại vi phạm ràng buộc logic (ví dụ: không bác sĩ nào trực ca). Không phải dirty write vì không ai ghi đè lên cùng một row, không phải lost update vì update không bị ghi mất — nhưng cuối cùng hệ thống vẫn sai.
⇒ Túm cái váy lại, bạn có thể hình dung thế này:
- Read skew là vấn đề ở bước đọc.
- Dirty write / Lost update là vấn đề ở bước ghi đè cùng một row.
- Write skew là vấn đề ở mức logic liên quan nhiều row — khó phát hiện và khó chống hơn, thường phải dùng Serializable isolation hoặc Explicit locking.
Và thường thì ta ít dùng Serializable isolation vì nó dường như là giải pháp cuối cùng vì nó đánh đổi bằng performance của hệ thống. Trong những trường hợp như write skew, explicit locking (hay select for update) là giải pháp phổ biến:
BEGIN TRANSACTION;
-- Lock tất cả bác sĩ đang on-call trong ca
SELECT * FROM doctors
WHERE on_call = true
AND shift_id = 1234
FOR UPDATE;
-- Alice xin nghỉ
UPDATE doctors
SET on_call = false
WHERE name = 'Alice'
AND shift_id = 1234;
COMMIT;
Phantoms
Có vẻ như explicit locking đang trở thành silver bullet cho các tình huống write race condition nếu bỏ qua các vấn đề về hiệu năng hoặc khả năng gây deadlock.
Liệu có thực sự như vậy, ta hãy cùng xem xét ví dụ sau:
Giả sử Alice (quản lý tài chính) muốn phân bổ toàn bộ ngân sách còn lại cho các dự án. Đầu tiên cô kiểm tra tổng ngân sách đã được phân bổ:
BEGIN;
SELECT SUM(allocated_amount) FROM budget_allocation
WHERE year = 2025; *-- trả về 800,000 USD*
Alice tính toán: ngân sách tổng là 1,000,000 USD, đã phân bổ 800,000 USD, còn lại 200,000 USD. Cô chuẩn bị phân bổ toàn bộ số còn lại cho dự án mới.
Nhưng trong lúc đó, transaction khác (của Bob) đã thêm một khoản phân bổ khẩn cấp:
*-- Transaction của Bob (đã commit)*
INSERT INTO budget_allocation(project_name, allocated_amount, year)
VALUES ('Emergency IT Upgrade', 150000, 2025);
Alice kiểm tra lại để confirm trước khi thực hiện phân bổ cuối cùng:
SELECT SUM(allocated_amount) FROM budget_allocation
WHERE year = 2025; *-- bây giờ trả về 950,000 USD*
Record "Emergency IT Upgrade" xuất hiện như một "bóng ma" giữa hai lần đọc trong cùng một transaction của Alice, mặc dù Alice không hề thay đổi gì. Đây chính là đặc trưng của phantom read - các record mới được INSERT bởi transaction khác làm thay đổi kết quả của cùng một truy vấn.
Nếu lúc này, Alice vẫn thực hiện theo kế hoạch ban đầu thì tổng ngân sách được phân bổ là 1,150,000 USD nhưng chỉ có 1,000,000 USD, dẫn đến thâm hụt ngân sách 150,000 USD.
INSERT INTO budget_allocation(project_name, allocated_amount, year)
VALUES ('Marketing Campaign', 200000, 2025);
COMMIT;
Ở đây, vấn đề là query ban đầu (SELECT …) dựa trên sự vắng mặt của dữ liệu, nên SELECT FOR UPDATE không có tác dụng: khi không có row nào trả về, thì cũng không có gì để khóa. Nhưng transaction khác vẫn có thể chèn vào một row “ma” (phantom row), làm điều kiện tìm kiếm thay đổi một cách bất ngờ.
Nói cách khác:
- Với write skew, bạn còn có cái để khóa (những row được đọc ở bước 1).
- Với phantom, bạn chẳng có gì để khóa, nhưng kết quả tìm kiếm lại có thể bị “ma nhập” khi row mới xuất hiện.
Và hiện tượng này được gọi là phantom.
💡Phantoms hay phantom read là một vấn đề khác có thể xảy ra trong các hệ thống cơ sở dữ liệu. Phantom xảy ra khi một giao dịch đọc một tập hợp dữ liệu nhiều lần, nhưng kết quả trả về khác nhau do một giao dịch khác đã thêm hoặc xóa dữ liệu trong tập hợp đó.
Nghe qua thì bạn có thể dễ bị nhầm lẫn với read skew (non-repeatable read) vì cả hai đều dẫn tới chuyện “kết quả query không nhất quán” giữa các transaction. Nhưng bản chất thì khác nhau một chút:
- Read skew: vấn đề đến từ thay đổi giá trị của row đã có, bạn đọc cùng một điều kiện 2 lần, và do transaction khác commit update/insert/delete xen vào row vừa đọc nên bạn thấy kết quả khác nhau.
- Phantom: vấn đề đến từ sự xuất hiện hoặc biến mất của row mới phù hợp với điều kiện tìm kiếm. Trong cùng một transaction, bạn chạy một query dựa trên một điều kiện (ví dụ “tìm tất cả doctor đang on_call = true” hoặc “tính tổng ngân sách 2025”)
Cách phòng tránh Phantom Reads
- Range Lock/Predicate Lock
BEGIN;
-- Lock toàn bộ range WHERE year = 2024
SELECT SUM(allocated_amount) FROM budget_allocation
WHERE year = 2024 FOR UPDATE;
-- Ngăn INSERT/DELETE mới trong range này
COMMIT;- Ưu điểm: Chính xác, chỉ lock phạm vi cần thiết
- Nhược điểm: Phức tạp, không phải database nào cũng hỗ trợ tốt
- Table Lock
BEGIN;
LOCK TABLE budget_allocation IN EXCLUSIVE MODE;
SELECT SUM(allocated_amount) FROM budget_allocation WHERE year = 2024;
-- Không ai có thể INSERT/UPDATE/DELETE cho đến khi commit
COMMIT;- Ưu điểm: Đảm bảo không có phantom
- Nhược điểm: Hiệu năng kém, block toàn bộ table
- Optimistic Concurrency với Versioning
BEGIN;
-- Đọc dữ liệu và version hiện tại
SELECT SUM(allocated_amount), MAX(version) AS current_version
FROM budget_allocation WHERE year = 2024;
-- ... xử lý logic ...
-- Kiểm tra version không thay đổi trước khi commit
SELECT MAX(version) FROM budget_allocation WHERE year = 2024;
-- Nếu version khác current_version thì ROLLBACK
COMMIT;- Ưu điểm: Không block, hiệu năng tốt
- Nhược điểm: Phải retry nếu conflict, cần thêm version column
- Serializable Isolation Level
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN;
SELECT SUM(allocated_amount) FROM budget_allocation WHERE year = 2024;
-- Hệ thống tự động phát hiện và ngăn phantom reads
COMMIT;
- Ưu điểm: Tự động, không cần code thêm
- Nhược điểm: Hiệu năng thấp nhất, nhiều retry
3.5. Serializability
Cho đến nay, chúng ta đã thấy nhiều ví dụ về các transaction dễ rơi vào tình trạng race condition. Một số race condition được ngăn chặn bởi isolation level read committed và snapshot isolation, nhưng một số khác thì không. Ta đã gặp những trường hợp đặc biệt rắc rối như write skew và phantom.
Và đó chính là “cơn đau đầu” của giới lập trình viên lẫn DBA suốt mấy chục năm qua:
- Isolation level vốn đã khó hiểu, mà mỗi database lại “chế biến” khác nhau (điển hình: “repeatable read” ở hệ này có thể không giống ở hệ kia).
- Nhìn vào code ứng dụng thì rất khó biết chắc liệu nó có “an toàn” ở isolation level hiện tại hay không. Càng là ứng dụng lớn, càng nhiều thứ chạy song song mà bạn không thể nắm hết.
- Công cụ để phát hiện race condition thì… gần như không có. Lý thuyết có nói đến static analysis, nhưng trên thực tế vẫn chưa có giải pháp “ra lò” nào hữu ích. Còn kiểm thử thì lại cực khó, vì bug concurrency thường chỉ xảy ra khi timing “xui rủi”.
Thực ra đây chẳng phải vấn đề mới mẻ gì: nó đã tồn tại từ tận những năm 1970, khi các weak isolation level lần đầu ra đời. Và từ ngày đó, các nhà nghiên cứu luôn nhắc đi nhắc lại một câu trả lời rất giản đơn: hãy dùng serializable isolation :v
Serializable isolation được xem là mức mạnh nhất: nó đảm bảo rằng dù transaction có chạy song song, kết quả cuối cùng vẫn y như thể chúng được chạy tuần tự, từng cái một. Nghĩa là, nếu transaction chạy riêng lẻ thì đúng, thì khi chạy cùng nhau cũng vẫn đúng. Hay nói cách khác: serializable isolation bịt kín toàn bộ lỗ hổng race condition.
Tại sao không phải ai cũng sử dụng serializable isolation level?
Nghe thì ngon thật. Nhưng nếu đã tuyệt vời thế, sao nó không được sử dụng rộng rãi? Đơn giản vì cái gì mạnh nhất thì thường… phức tạp và tốn nhiều chi phí nhất. Và câu trả lời nằm ở performance và implementation complexity.
Các thách thức chính:
- Performance overhead: Để đảm bảo serializability, database phải thực hiện nhiều kiểm tra và locking hơn
- Deadlock tăng: Càng nhiều lock, càng dễ xảy ra deadlock
- Throughput giảm: Ít transactions có thể chạy đồng thời
- Complexity: Implementation phức tạp hơn nhiều
Để thực thi serializability, hầu hết các database hiện tại sử dụng một trong ba kỹ thuật sau:
- Thực thi tuần tự: Chạy từng transaction một cách tuần tự, không có concurrency nào cả.
- Khóa hai pha (2PL): Một kỹ thuật đã được sử dụng trong nhiều thập kỷ, đó là sử dụng hệ thống lock phức tạp để đảm bảo serializable order. Tất nhiên, lock càng nhiều thì khả năng xảy ra deadlock càng cao :v
- Optimistic concurrency control - cho phép transactions chạy song song, detect conflicts sau đó abort nếu cần.: Chẳng hạn như Serializable Snapshot Isolation (SSI).
Vì bài viết cũng đủ dài rồi, nên nếu bạn muốn tìm hiểu sâu hơn vì những kỹ thuật này thì hãy comment ở dưới bài viết để thảo luận thêm nha, hoặc cũng có thể xem ở mục references.
Còn bây giờ thì mình sẽ summary lại một chút các nội dung chúng ta đã cùng tìm hiểu trong post này �🏻♂️
4. Summary
Trong bài viết này, mình đã cùng các bạn tìm hiểu
Transaction và ACID
Transaction là gì?
- Định nghĩa: Nhóm các thao tác đọc/ghi thành một đơn vị logic thống nhất
- Nguyên tắc: "All or nothing" - hoặc tất cả thành công, hoặc không có gì được áp dụng
ACID Properties
Atomicity (Tính nguyên tử)
- Đảm bảo: Transaction được xử lý như một đơn vị không thể chia nhỏ
- Ví dụ: Email system - ghi email mới + tăng counter phải cùng thành công hoặc cùng thất bại
- Lợi ích: Tránh trạng thái không đồng nhất khi có lỗi xảy ra
Consistency (Tính nhất quán)
- Bản chất: Phụ thuộc vào ứng dụng, không chỉ database
- Database role: Thực thi constraints (foreign keys, check constraints)
- Application role: Đảm bảo business logic invariants
Isolation (Tính cô lập)
- Mục đích: Các transaction chạy độc lập như thể không có concurrency
- Vấn đề giải quyết: Race conditions, dirty reads, lost updates
- Các mức độ: Read Uncommitted → Read Committed → Repeatable Read → Serializable
Durability (Tính bền vững)
- Đảm bảo: Data đã commit sẽ không mất ngay cả khi có hardware failure
- Thực tế: Không tồn tại durability hoàn hảo (all disks + backups destroyed)
Các loại race condition và cách phòng tránh
- Dirty read: Giao dịch SQL T1 thay đổi một dòng. Giao dịch SQL T2 sau đó đọc dòng đó trước khi T1 thực hiện COMMIT. Nếu T1 sau đó thực hiện ROLLBACK, T2 sẽ đã đọc một dòng không bao giờ được commit, hay nói cách khác là dữ liệu đó chưa bao giờ tồn tại.
- Dirty Write: Giao dịch SQL T1 thay đổi một dòng. Giao dịch SQL T2 sau đó ghi đè lên cùng dòng đó trước khi T1 thực hiện COMMIT hoặc ROLLBACK. Điều này có thể dẫn đến việc mất dữ liệu của T1 và tạo ra trạng thái không nhất quán, vì giá trị cuối cùng phụ thuộc vào thứ tự commit của các giao dịch mà không có sự kiểm soát thích hợp.
- Lost Update (Mất cập nhật): Giao dịch SQL T1 đọc một dòng dữ liệu. Giao dịch SQL T2 cũng đọc cùng dòng đó. Sau đó T1 thay đổi dòng này dựa trên giá trị đã đọc và thực hiện COMMIT. Tiếp theo, T2 cũng thay đổi cùng dòng đó dựa trên giá trị mà nó đã đọc trước đó (không phải giá trị mới nhất sau khi T1 commit) và thực hiện COMMIT. Kết quả là việc cập nhật của T1 bị "mất" hoàn toàn, vì T2 đã ghi đè lên nó mà không biết về sự thay đổi của T1.
→ Điểm khác biệt giữa Lost Update khác và Dirty Write là cả hai giao dịch đều đọc giá trị cũ trước khi ghi (lost update), thay vì một giao dịch ghi đè trực tiếp lên giá trị chưa commit của giao dịch khác (dirty write).
- Non-repeatable read: Giao dịch SQL T1 đọc một dòng. Giao dịch SQL T2 sau đó thay đổi hoặc xóa dòng đó và thực hiện COMMIT. Nếu T1 sau đó cố gắng đọc lại dòng đó, nó có thể nhận được giá trị đã thay đổi hoặc phát hiện ra rằng dòng đã bị xóa.
- Phantom: Giao dịch SQL T1 đọc tập hợp N dòng thỏa mãn một điều kiện nào đó. Giao dịch SQL T2 sau đó thực thi các câu lệnh SQL tạo ra một hoặc nhiều dòng thỏa mãn điều kiện được sử dụng bởi giao dịch SQL T1. Nếu giao dịch SQL T1 sau đó lặp lại việc đọc ban đầu với cùng điều kiện, nó sẽ thu được một tập hợp dòng khác.
- Write Skew: Giao dịch SQL T1 đọc một tập hợp dòng và dựa trên kết quả đó để ghi vào một dòng khác. Đồng thời, giao dịch SQL T2 cũng đọc một tập hợp dòng (có thể trùng lặp với T1) và ghi vào một dòng khác nữa. Mặc dù hai giao dịch không ghi vào cùng một dòng, nhưng các thay đổi của chúng khi kết hợp lại có thể vi phạm một ràng buộc toàn vẹn (integrity constraint) hoặc quy tắc nghiệp vụ mà mỗi giao dịch đều tưởng rằng mình đang tuân thủ.
Ví dụ: Hai bác sĩ đều kiểm tra và thấy có đủ người trực, sau đó cùng xin nghỉ → Kết quả: không còn ai trực ca.
| Isolation Level | Dirty Read | Non-repeatable Read | Phantom Read | Write Skew |
|---|---|---|---|---|
| Read Uncommitted | Possible | Possible | Possible | Possible |
| Read Committed | Prevented | Possible | Possible | Possible |
| Repeatable Read | Prevented | Prevented | Possible | Possible |
| Serializable | Prevented | Prevented | Prevented | Prevented |
Như mình đã đề cập từ đầu bài viết, "ACID database" không tự động giải quyết tất cả concurrency issues. Hiểu rõ isolation levels và race conditions là chìa khóa để chúng ta xây dựng reliable applications. Dưới đây là một số key tạkeaways mà mình nghĩ bạn có thể cần đến:
Lựa chọn Isolation Level
- Read Committed → Lựa chọn mặc định của hầu hết ứng dụng, cân bằng tốt giữa tính đúng đắn và hiệu năng.
- Snapshot Isolation → Phù hợp cho các truy vấn dài hơi, workload dạng phân tích, nơi cần đọc dữ liệu ổn định trong suốt transaction.
- Serializable → Dành cho những tình huống cực kỳ quan trọng về tính đúng đắn, chấp nhận đánh đổi hiệu năng để đổi lấy sự an toàn tuyệt đối.
Best Practices
- Hiểu rõ trade-offs: Hiệu năng và tính đúng đắn luôn cần được cân nhắc đánh đổi
- Test kỹ concurrency scenarios: Race condition thường khó lặp lại trong test, nhưng khi đã xảy ra ở production thì hậu quả rất lớn.
- Theo dõi xung đột: Quan sát tỉ lệ abort, deadlock để biết khi nào hệ thống đang chịu áp lực đồng thời.
Tuy nhiên tất cả những gì chúng ta vừa phân tích chỉ áp dụng trong phạm vi một cơ sở dữ liệu đơn lẻ. Trong thế giới hệ thống phân tán, nơi dữ liệu và giao dịch trải rộng trên nhiều node và dịch vụ, câu chuyện còn phức tạp hơn nhiều. Đó cũng chính là lúc chúng ta phải đối mặt với một khái niệm mới: Distributed Transactions.
Trong bài viết sau, ta sẽ cùng nhau mổ xẻ về chủ đề này nhé. Còn bây giờ, happy weekend and thanks for reading 🥸
References
https://stackoverflow.com/questions/11043712/non-repeatable-read-vs-phantom-read
https://www.oreilly.com/library/view/designing-data-intensive-applications/9781491903063/
http://mbukowicz.github.io/databases/2020/05/01/snapshot-isolation-in-postgresql.html
https://medium.com/%40moali314/database-logging-wal-redo-and-undo-mechanisms-58c076fbe36e
https://www.alibabacloud.com/blog/comprehensive-understanding-of-transaction-isolation-levels_596894