By @AnhDH
Mục lục
Trong các hệ thống phân tán, việc đảm bảo tính nhất quán của dữ liệu (data consistency) và ngăn chặn tranh chấp tài nguyên (race condition) là một thách thức lớn, đặc biệt khi nhiều tiến trình hoặc service truy cập đồng thời vào các tài nguyên dùng chung. Một trong những giải pháp quan trọng để giải quyết vấn đề này chính là sử dụng distributed lock (khóa phân tán).
Bài viết này mình sẽ giúp bạn hiểu rõ distributed lock là gì, tại sao nó cần thiết, các phương pháp để thực hiện, và cách triển khai nó với Redis nhé.
Bắt đầu thôi.
1. Đặt vấn đề
Hãy tưởng tượng một hệ thống xử lý thanh toán ngân hàng, nơi có nhiều tiến trình cần cập nhật số dư của một tài khoản khi có giao dịch. Bài toán của mình sẽ như sau:
- User A đang có 1000$ trong tài khoản ngân hàng
- A thực hiện hai request đồng thời:
- Request 1: Rút 200$
- Request 2: Chuyển cho B 300$
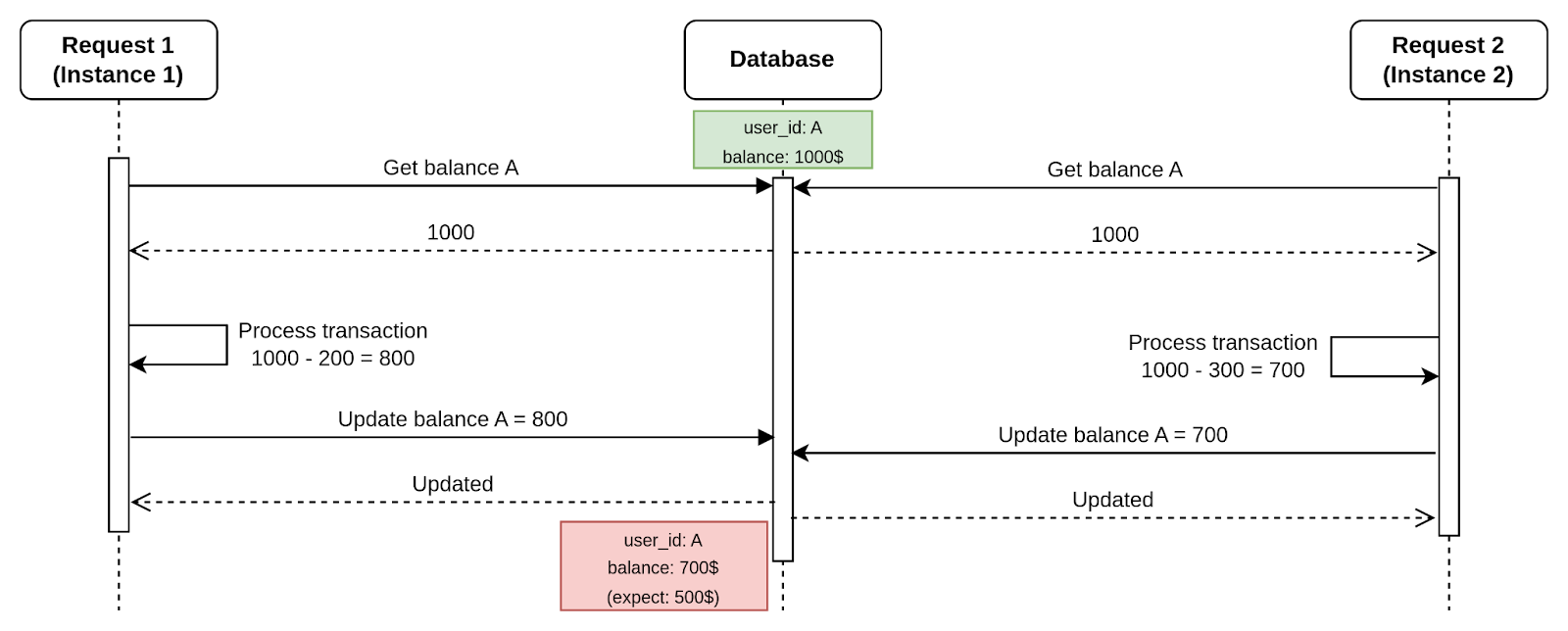
Từ sequence diagram bạn có thể thấy rằng:
- Hai request cùng lúc đọc số dư tài khoản của A:
- Request 1 đọc số dư: 1000$
- Request 2 đọc số dư: 1000$
- Request 1 rút tiền:
- Tính toán số dư mới: 1000 - 200 = 800
- Ghi lại số dư tài khoản là 800$ vào hệ thống
- Request 2 chuyển tiền (xử lý đồng thời cùng request 1):
- Tính toán số dư mới: 1000 - 300 = 700
- Ghi lại số dư tài khoản là 700$ vào hệ thống, ghi đè kết quả của request 1.
Thực tế, tổng số tiền A đã rút và chuyển là 200 + 300 = 500$ nhưng hệ thống ghi nhận số dư là 700$.
Chúng ta hãy xem đoạn code mẫu dưới đây có thể dễ hình dung hơn nhé.
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.CompletableFuture;
import lombok.SneakyThrows;
class DistributedLock {
static String USER_ID = "A";
static Map<String, Integer> USERS = new HashMap<>() {{
put(USER_ID, 1000);
}};
public static void main(String[] args) {
//
CompletableFuture.allOf(
CompletableFuture.runAsync(DistributedLock::fundOut),
CompletableFuture.runAsync(DistributedLock::fundTransfer)
).join();
// {A=700}
System.out.println(USERS);
}
static void fundOut() {
Integer balance = getBalance(USER_ID);
balance = balance - 200;
updateBalance(USER_ID, balance);
}
static void fundTransfer() {
Integer balance = getBalance(USER_ID);
balance = balance - 300;
updateBalance(USER_ID, balance);
}
@SneakyThrows
static Integer getBalance(String userId) {
Integer balance = USERS.get(userId);
Thread.sleep(1000L);
return balance;
}
static void updateBalance(String userId, Integer balance) {
USERS.put(userId, balance);
}
}Với cách làm hiện tại thì hệ thống trên đang gặp hai vấn đề:
- Race condition: Cả hai request cùng truy cập và thao tác trên tài nguyên dùng chung (số dư tài khoản) mà không có sự điều phối.
- Data inconsistency: Hệ thống không ghi nhận đúng số dư sau khi các giao dịch hoàn thành.
Giải pháp cho bài toán này là xử lý tuần tự hai request để đảm bảo rằng chỉ một tiến trình được phép truy cập tài nguyên tại một thời điểm. Đây cũng chính là mục đích của distributed lock.
2. Distributed Lock
2.1. Distributed Lock là gì?
Distributed Lock là một cơ chế kiểm soát quyền truy cập vào các tài nguyên dùng chung trong một hệ thống phân tán. Không giống như các cơ chế lock truyền thống chỉ hoạt động trong phạm vi một instance, distributed lock đảm bảo rằng tại một thời điểm chỉ có một tiến trình duy nhất có thể truy cập vào tài nguyên, bất kể các tiến trình này đang chạy trên một hay nhiều server khác nhau. Cơ chế này giúp ngăn chặn xung đột, bảo vệ tính toàn vẹn của dữ liệu và duy trì sự nhất quán trong các môi trường phân tán phức tạp.
Để có thể hoạt động hiệu quả, Distributed Lock cần đảm bảo ba tính chất sau:
- Safety: Tại bất kỳ thời điểm nào, chỉ một tiến trình được phép lock tài nguyên. Điều này đảm bảo rằng không có hai tiến trình nào có thể đồng thời truy cập vào cùng một tài nguyên, tránh xảy ra các xung đột hoặc lỗi dữ liệu.
- Liveness: Khóa phải được giải phóng ngay khi tiến trình giữ khóa xử lý xong hoặc gặp sự cố. Điều này giúp ngăn chặn tình trạng tài nguyên bị khóa quá lâu.
- Availability: Các tiến trình khác trong hệ thống phải có khả năng lấy được khóa sau khi khóa được giải phóng.
2.2. Tại sao Distributed Lock quan trọng?
Trong các hệ thống phân tán, nhiều tiến trình có thể chạy trên một hoặc nhiều node khác nhau và cùng lúc truy cập vào một tài nguyên dùng chung. Điều này dễ dẫn đến các vấn đề như race condition, dữ liệu không nhất quán, hoặc hành vi không mong đợi. Distributed Lock chính là giải pháp để ngăn chặn các tình huống này, đảm bảo hệ thống hoạt động ổn định và đáng tin cậy.
Một số usecase thường sử dụng Distributed Lock như:
- Job Scheduling: Hệ thống phân tán thường bao gồm nhiều cron job, các cron job không nên được thực thi trên nhiều instance của service.
- Ngăn chặn update đổng thời vào Database: Khi nhiều tiến trình update một bản ghi cơ sở dữ liệu cùng lúc, Distributed Lock sẽ đảm bảo rằng chỉ có một thao tác ghi xảy ra tại một thời điểm.
- Ngăn chặn duplicate request: Vì nhiều lý do khác nhau như lỗi lập trình hoặc lỗi mạng mà request bị gửi duplicate. Nếu hai request giống nhau cùng gửi tới hệ thống thì Distributed Lock giúp reject request và chỉ xử lý một request còn lại.
2.3. Các phương pháp triển khai Distributed Lock
Có nhiều công nghệ và giải pháp được sử dụng để triển khai cơ chế Distributed Lock, mỗi giải pháp đều có những ưu và nhược điểm riêng. Dưới đây là một số các giải pháp phổ biến:
- Database-based Locking: Một phương pháp phổ biến là sử dụng cơ sở dữ liệu để lưu trữ thông tin khóa. Ví dụ, bạn có thể tạo một bảng để đánh dấu một tài nguyên nào đó có đang bị khóa hay không. Đây là một giải pháp đơn giản và có thể tích hợp dễ dàng vào hệ thống hiện có, nhưng cũng có thể bị giảm hiệu suất khi có quá nhiều thao tác đồng thời.
- Zookeeper-based Locking: Apache Zookeeper là một công cụ phổ biến trong các hệ thống phân tán, nó đảm bảo rằng các máy chủ (node) trong một hệ thống phân tán có thể làm việc cùng nhau một cách đồng bộ và nhất quán. Zookeeper hỗ trợ Distributed Lock thông qua việc sử dụng các ephemeral nodes (node tạm thời). Tuy Zookeeper đảm bảo tính nhất quán mạnh mẽ và đáng tin cậy, nhưng việc thiết lập và quản lý Zookeeper có thể phức tạp và tốn công.
- Redis-based Locking: Redis là một công cụ lưu trữ dữ liệu in-memory nhanh chóng và nhẹ, rất phổ biến trong việc triển khai Distributed Lock. Redis cung cấp cơ chế Distributed Lock giúp đảm bảo rằng chỉ một tiến trình có thể thiết lập giá trị cho một khóa nhất định nếu khóa đó chưa tồn tại. Redis rất thích hợp cho các hệ thống yêu cầu tốc độ cao, với độ trễ thấp và dễ dàng cấu hình. Tuy nhiên, cần phải xử lý cẩn thận các trường hợp đặc biệt như deadlock hoặc khóa bị hết hạn.
Trong các giải pháp trên, Redis là sự lựa chọn phổ biến nhất nhờ vào sự đơn giản, tốc độ và khả năng mở rộng của nó.
3. Triển khai Distributed Lock với Redis
Chúng ta cùng quay lại bài toán ban đầu của mình và cùng xem giải pháp triển khai distributed lock với redis thông qua sơ đồ bên dưới đây nhé.
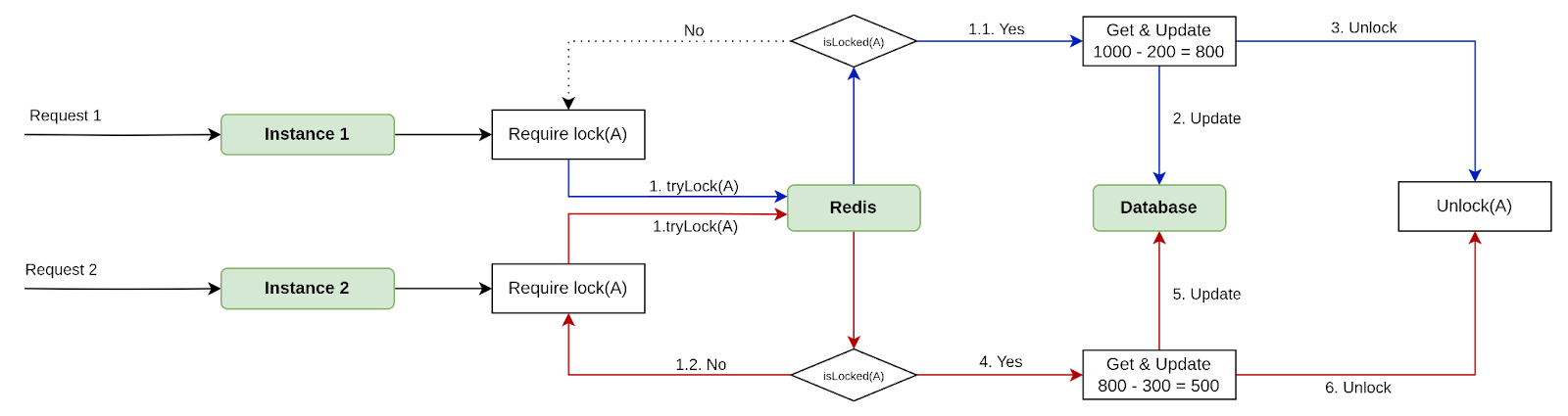
Lúc này, quy trình xử lý hai request sẽ diễn ra như sau:
- Request 1 và 2 cùng yêu cầu tạo một khóa trên redis để lock user_id của A:
- Request 1 tạo được khóa trước ⇒ Request 1 được xử lý (bước 1.1)
- Request 2 phải chờ khi request 1 giải phóng khóa hoặc khi khóa hết hạn (Request 2 lặp lại bước 1 yêu cầu tạo khóa)
- Request 1 hoàn tất xử lý:
- Tính toán số dư mới: 1000 - 200 = 800
- Ghi lại số dư tài khoản là 800$ vào hệ thống
- Giải phóng khóa trong redis
- Request 2 tạo được khóa và tiến hành xử lý giao dịch
- Tính toán số dư mới: 800 - 300 = 500
- Ghi lại số dư tài khoản là 500$ vào hệ thống
- Giải phóng khóa trong redis
Chúng ta có thể khái quát quy trình xử lý request kết hợp với cơ chế Distributed Lock thông qua đoạn code dưới đây.
func update() {
try {
// Try lock "key" with TTL = X seconds in Y seconds
if(tryLock(key, value, X, Y)) {
// Handle get, calculate and update resource
// Return
}
} finally {
unLock(key, value)
}
//
throw Exception("Try lock timeout")
}Ở đoạn code trên, ta sẽ có 2 function tryLock() và unlock() để triển khai cơ chế distributed lock. Trước khi thực hiện logic chính, hàm tryLock sẽ phải yêu cầu tạo khóa trong redis với TTL của khóa là X (s). Nếu khóa không được tạo, tryLock sẽ liên tục cố gắng thử tạo lại khóa trong vòng Y (s), nếu tạo được khóa thì logic tiếp theo sẽ được thực thi, còn không thì sẽ dừng lại và kết thúc xử lý.
Có hai cách tiếp cận phổ biến để có thể triển khai distributed lock với redis đó là sử dụng lệnh SET với tham số NX và thư viện Redision. Mỗi cách tiếp cận đều có các ưu, nhược điểm riêng, tùy thuộc vào các yêu cầu cụ thể của hệ thống, mức độ quen thuộc của bạn khi sử dụng. Hiểu được những điều này sẽ giúp bạn đưa ra quyết định sáng suốt phù hợp nhất với nhu cầu của dự án.
3.1. Sử dụng lệnh SET với tham số NX
Cách đơn giản nhất để triển khai distributed lock với Redis là sử dụng lệnh SET với tham số NX. Lệnh này chỉ set một key với value nhất định nếu key đó chưa tồn tại. Bằng cách này, chúng ta sẽ set key duy nhất trong Redis đại diện cho tài nguyên được khóa. Nếu key được set thành công, khóa sẽ được lấy. Ngược lại, khóa đã được lấy bởi một tiến trình khác. Tiến trình hiện tại phải đợi khóa được giải phóng.
Các câu lệnh của redis mình sẽ sử dụng bao gồm:
- Lock:
SET lock_key value NX PX ttl- ttl: Là thời gian hết hạn của khóa. Khóa sẽ được giải phóng sau khoảng ttl miliseconds.
- Nếu set thành công, lệnh trên trả về OK, ngược lại sẽ trả về (nil).
- Unlock:
DEL (UNLINK) lock_key: Xóa khóa, bỏ qua nếu khóa không tồn tại.
Để triển khai phương pháp này, chúng ra sẽ sử dụng thư viện jedis. Đây là một thư viện redis-client đơn giản, gọn nhẹ, có cộng đồng support lớn và được khuyên dùng sử dụng bởi chính trang chủ redis, ngoài ra nó cũng được hỗ trợ chính thức bởi Spring Data Redis.
import lombok.SneakyThrows;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.params.SetParams;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.CompletableFuture;
class DistributedLock {
static String USER_ID = "A";
static Map<String, Integer> USERS = new HashMap<>() {{
put(USER_ID, 1000);
}};
static JedisPool jedisPool = new JedisPool(new JedisPoolConfig(), "localhost", 6379);
public static void main(String[] args) {
//
CompletableFuture.allOf(
CompletableFuture.runAsync(() -> lock(DistributedLock::fundOut)),
CompletableFuture.runAsync(() -> lock(DistributedLock::fundTransfer))
).join();
// {A=500}
System.out.println(USERS);
}
static void fundOut() {
Integer balance = getBalance(USER_ID);
balance = balance - 200;
updateBalance(USER_ID, balance);
}
static void fundTransfer() {
Integer balance = getBalance(USER_ID);
balance = balance - 300;
updateBalance(USER_ID, balance);
}
@SneakyThrows
static Integer getBalance(String userId) {
Integer balance = USERS.get(userId);
Thread.sleep(1000L);
return balance;
}
static void updateBalance(String userId, Integer balance) {
USERS.put(userId, balance);
}
static void lock(Runnable runnable) {
try {
if (!tryLock(USER_ID, 3000, 4000)) {
return;
}
//
runnable.run();
} finally {
unlock(USER_ID);
}
}
static boolean tryLock(String lockKey, int lockExpire, int tryLockTimeOut) {
try (Jedis jedis = jedisPool.getResource()) {
//
long start = System.currentTimeMillis();
//
while (true) {
//
String lockRes = jedis.set(lockKey, “1”, new SetParams().nx().px(lockExpire));
//
if (lockRes != null) {
return true;
}
//
if (System.currentTimeMillis() - start > tryLockTimeOut) {
throw new RuntimeException("Try lock timeout");
}
}
}
}
static void unlock(String lockKey) {
try (Jedis jedis = jedisPool.getResource()) {
jedis.del(lockKey);
}
}
}
Hãy so sánh với đoạn code ban đầu trong phần “Đặt vấn đề”, mình đã thêm vào các phần sau:
- Bổ xung phương thức lock() để áp dụng distributed lock vào hai hàm fundOut() và fundTransfer(). Hàm lock() sẽ có tác dụng wrap lại logic của hai hàm chuyển tiền và rút tiền. Trước khi hai hàm này thực hiện logic chính, thì sẽ phải yêu cầu tạo khóa trong redis với TTL của khóa là 3s. Hàm nào lấy được khóa trước thì sẽ được thực hiện trước. Hàm còn lại sẽ liên tục cố gắng thử lấy lại khóa trong vòng 4s, nếu lấy được khóa thì logic chính sẽ được thực thi, còn không thì logic chính sẽ không được thực hiện.
- Trong phương thức tryLock(), mình đã sử dụng vòng lặp white để tạo khóa bằng cách liên tục gọi lại câu lệnh SET với tham số NX. Nếu lấy được khóa trong khoảng thời gian chờ cho phép thì sẽ trả về true, ngược lại sẽ trả về lỗi.
- Trong phương thức unlock(), mình gọi lệnh DEL để xóa khóa sau khi thực hiện xong logic update. Nếu có lỗi xảy ra trong quá trình thực thi logic, khóa cũng sẽ được xóa khỏi redis để tránh tính trạng tài nguyên bị khóa.
Sau khi triển khai xong và run lại code, kết quả lúc này đã được ghi nhận là {A=500} thay vì {A=700} như trước. Điều này chứng tỏ rằng sau khi áp dụng cơ chế distributed lock, dữ liệu về số dư của user A đã được cập nhật đúng.
Phương pháp sử dụng lệnh SET với tham số NX và DEL đem lại sự đơn giản, hiệu quả và nhanh chóng. Truy nhiên, chúng ta sẽ cần phải hiểu bản chất và phải tự viết code để triển khai và bảo trì code về sau.
3.2. Sử dụng thư viện Redisson
Redisson là một thư viện Java mạnh mẽ được thiết kế để làm việc với Redis, nó cung cấp các API đơn giản và trừu tượng hóa các logic phức tạp bên trong, giúp cho lập trình viên có thể dễ dàng sử dụng mà không cần quá quan tâm vào logic triển khai. Một trong những tính năng nổi bật mà Redisson mang lại chính là cơ chế distributed locking, giúp đồng bộ hóa các tác vụ trong môi trường phân tán, đảm bảo tính toàn vẹn của dữ liệu và tăng cường hiệu suất cho các hệ thống quy mô lớn.
Dưới đây là đoạn code minh họa sử dụng thư viện Redisson để triển khai distributed lock.
import lombok.SneakyThrows;
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.TimeUnit;
class DistributedLock {
// ...
static RedissonClient redissonClient;
static {
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
redissonClient = Redisson.create(config);
}
public static void main(String[] args) {
//
CompletableFuture.allOf(
CompletableFuture.runAsync(() -> lock(DistributedLock::fundOut)),
CompletableFuture.runAsync(() -> lock(DistributedLock::fundTransfer))
).join();
// {A=500}
System.out.println(USERS);
}
static void lock(Runnable runnable) {
RLock lock = redissonClient.getLock(USER_ID);
try {
// Try to acquire the lock with a timeout of 3 seconds and lease time of 4 seconds
if (lock.tryLock(3, 4, TimeUnit.SECONDS)) {
runnable.run();
}
} finally {
lock.unlock();
}
}
// ...
}Ở đoạn code phía trên mình đã remove đi hai hàm tryLock() và unlock() do mình đã tạo ra trước đó và sử dụng hàm tryLock() và unlock() của thư viện redission. Các bạn có thể thấy rằng đoạn code đã trở lên ngắn hơn đáng kể và cũng dễ đọc hơn. Redision đem lại sự đơn giản, tiện lợi nhưng nó có thể sẽ tốn tài nguyên hơn so với các phương pháp triển khai bằng cách sử dụng lệnh redis, tuy nhiên điều này cũng không quá đáng kể. Bên cạnh đó, do nó có tính trừu tượng hóa cao nên ta cũng sẽ khó kiểm soát hơn các khóa và các logic được thực thi bên phía trong.
4. Best practice
Trong phần này, mình sẽ đưa ra một số các best practice khi triển khai distributed lock với redis. Những lời khuyên này sẽ giúp bạn tối ưu hóa hiệu suất của hệ thống, đảm bảo tính nhất quán dữ liệu và khả năng chịu lỗi trong môi trường phân tán.
- Đặt thời gian hết hạn (TTL) hợp lý cho khóa (không nên đặt quá lâu).
- Luôn unlock khóa khi kết thúc logic xử lý hoặc có bất kỳ lỗi nào xảy ra.
- Nên sử dụng distributed lock đúng nơi, đúng chỗ, tránh lạm dụng distributed lock vì có thể khiến hệ thống tăng độ trễ khi xử lý.
- Nên start một transaction bên trong distributed lock.
- Triển khai Redis Cluster để đảm bảo tính sẵn sàng (high availability) và tăng độ tin cậy (reliability).
5. Tổng kết
- Distributed Lock là giải pháp thiết yếu để đảm bảo tính toàn vẹn dữ liệu, tránh race condition và thường được sử dụng trong các bài toán như job scheduling, ngăn chặn duplicate request và xử lý tuần tự logic cập nhật dữ liệu.
- Redis-based Locking là lựa chọn phổ biến nhờ tốc độ nhanh và khả năng xử lý các thao tác dữ liệu mạnh mẽ. Có hai cách tiếp cận chính là sử dụng lệnh SET với tham số NX và thư viện Redisson. Mỗi phương pháp đều có sự đánh đổi riêng và chọn phương pháp nào tùy thuộc vào yêu cầu cụ thể của hệ thống.
- Sử dụng distributed lock đúng chỗ và luôn giải phóng khóa ngay khi kết thúc logic hoặc có lỗi xảy ra.
Đến đây là kết thúc bài viết rồi. Dù nội dung khá dài, mình hy vọng những chia sẻ trên đây sẽ mang đến cho bạn những kiến thức mới mẻ và giá trị, giúp bạn áp dụng hiệu quả vào các dự án thực tế.
Hẹn gặp lại các bạn trong các bài viết sắp tới nhé.
Happy reading! 🍻
6. Tham khảo
[1] Distributed lock | Redis.io
✏️ System Design VN: https://fb.com/groups/systemdesign.vn
📚 Đọc thêm tài liệu khác: https://roninhub.com/tai-lieu
🎬 Youtube: https://youtube.com/@ronin-engineer
🎞️ TikTok: https://tiktok.com/@ronin.engineer